Chapter 4
Machine Learning Crates in Rust Ecosystem
"The true sign of intelligence is not knowledge but imagination." — Albert Einstein
Chapter 4 of MLVR introduces the essential crates in the Rust ecosystem that are crucial for building, training, evaluating, and interpreting machine learning models. Starting with an overview of the role crates play in extending Rust’s capabilities, the chapter explores data processing, linear algebra, machine learning model implementation, model evaluation, and data visualization. Each section combines theoretical knowledge with practical examples, demonstrating how to integrate these crates into robust machine learning pipelines. By the end of this chapter, readers will be well-equipped to leverage Rust’s ecosystem for a wide range of machine learning tasks.
4.1 Overview of Machine Learning Crates in Rust
The Rust ecosystem has gained considerable traction in recent years, becoming a powerful language choice for systems programming and, more recently, for machine learning applications. The concept of crates, which are Rust's libraries or packages, is central to the Rust ecosystem. Crates allow developers to extend the capabilities of Rust by leveraging pre-existing code, promoting code reuse, and fostering community collaboration. This modularity makes it easier to implement complex functionalities without having to build everything from scratch. In the context of machine learning, leveraging crates can accelerate development and allow developers to focus on designing algorithms and models rather than the underlying implementations.
Choosing the right crates for a specific machine learning task can be daunting, given the variety of options available. Each crate often serves a particular purpose, such as data manipulation, model training, or performance optimization. When selecting a crate, it is essential to consider factors such as the crate's performance, ease of use, community support, and the frequency of updates. The structure of a crate typically includes a Cargo.toml file that contains metadata about the crate, dependencies, and versioning information. Understanding this structure can help developers navigate the ecosystem effectively and make informed decisions.
Documentation is a critical component of any crate. Well-documented crates provide clear instructions on how to implement features, APIs, and examples, which is especially beneficial for those new to Rust or machine learning. The Rust community places a strong emphasis on documentation, and crates that lack thorough documentation may not be suitable for integration into a project. Additionally, versioning plays a crucial role in the stability and reliability of a crate. Developers need to be mindful of the versioning strategy of the crates they choose, as breaking changes can lead to significant issues in their projects. Community support is also indispensable; a crate with an active community is likely to have a wealth of resources, tutorials, and forums for troubleshooting.
To get started with machine learning in Rust, developers can utilize Cargo, Rust’s package manager, which simplifies the process of installing and managing crates. For instance, to include a machine learning crate like ndarray—which provides N-dimensional arrays in Rust—one can modify the Cargo.toml file as follows:
[dependencies]
ndarray = "0.15"
After adding the dependency, running cargo build will automatically download and compile the crate, making it ready for use in the project. Furthermore, the crates.io repository serves as the central hub for discovering and managing Rust crates. Developers can search for machine learning libraries by entering relevant keywords or categories, allowing them to find the most suitable options for their projects.
Once the necessary crates are identified and added to the project, setting up the Rust project becomes straightforward. For example, consider a simple project that utilizes both the ndarray and linfa crates—where linfa offers machine learning algorithms. The project structure might look like this:
my_ml_project/
├── Cargo.toml
└── src/
└── main.rs
The Cargo.toml file would include the following dependencies:
[dependencies]
ndarray = "0.15"
linfa = "0.7.0"
linfa-linear = "0.7.0"
In the main.rs file, you could implement a simple linear regression model using these crates:
use linfa::{traits::Fit, Dataset};
use linfa_linear::LinearRegression;
use ndarray::{Array1, Array2};
fn main() {
let x = Array2::from_shape_vec((4, 2), vec![1.0, 1.0, 1.0, 2.0, 1.0, 3.0, 1.0, 4.0]).unwrap();
let y = Array1::from_shape_vec(4, vec![1.0, 2.0, 3.0, 4.0]).unwrap();
let dataset = Dataset::new(x, y);
let model = LinearRegression::default().fit(&dataset).unwrap();
println!("Model coefficients: {:?}", model.params());
}
In this example, we first import the necessary modules from ndarray and linfa. We then create a dataset using ndarray and fit a linear regression model using the linfa library. The output will display the model coefficients, demonstrating how these crates can seamlessly work together to provide machine learning functionalities.
In conclusion, the Rust ecosystem offers a rich set of machine learning crates that empower developers to build efficient and scalable applications. By understanding the fundamental, conceptual, and practical aspects of these crates, one can effectively choose and utilize them in their projects. As the ecosystem continues to evolve, it is crucial for developers to stay informed about new developments, community best practices, and emerging libraries to fully harness the potential of machine learning in Rust.
4.2 Data Processing and Manipulation Crates
In the realm of machine learning, data preprocessing forms the backbone of any successful model. This phase is critical as it ensures that the data fed into algorithms is in an optimal state for learning. The importance of preprocessing cannot be overstated; it encompasses various tasks such as handling different data types—both structured and unstructured—along with performing essential transformations that prepare the data for analysis. This includes scaling, normalization, and encoding, all of which significantly influence the performance of machine learning models. In Rust, several crates facilitate these preprocessing tasks, allowing developers to efficiently manipulate and transform data.
To begin with, Rust's ecosystem provides a rich set of libraries that cater to different aspects of data manipulation. Among these, the serde crate is a cornerstone for serialization and deserialization. It allows Rust structures to be converted to and from various data formats, such as JSON and TOML, making it easier to handle different data types. For instance, when working with structured data, serde can be used to serialize complex Rust data structures into formats that can be easily stored or transmitted.
Here's a brief example of how one might use serde to serialize a simple Rust struct into JSON:
// Append Cargo.toml
[dependencies]
serde = { version = "1.0.210", features = ["derive"] }
serde_json = "1.0.128"
use serde::{Deserialize, Serialize};
#[derive(Serialize, Deserialize)]
struct User {
id: u32,
name: String,
}
fn main() {
let user = User {
id: 1,
name: String::from("Alice"),
};
let serialized = serde_json::to_string(&user).unwrap();
println!("Serialized: {}", serialized);
let deserialized: User = serde_json::from_str(&serialized).unwrap();
println!("Deserialized: {} - {}", deserialized.id, deserialized.name);
}
In this example, the User struct is defined, and serde is used to convert it to a JSON string and then back to a Rust object. This showcases the fundamental idea of handling structured data effectively through serialization, which is crucial in preparing data for machine learning tasks.
When it comes to handling tabular data, the csv crate is indispensable. It simplifies reading from and writing to CSV files, which are a common format for datasets in machine learning. The following example demonstrates how to read a CSV file containing user data:
// Append Cargo.toml
[dependencies]
csv = "1.3.0"
use csv::ReaderBuilder;
use std::error::Error;
fn read_csv(file_path: &str) -> Result<(), Box<dyn Error>> {
let mut rdr = ReaderBuilder::new().has_headers(true).from_path(file_path)?;
for result in rdr.records() {
let record = result?;
println!("{:?}", record);
}
Ok(())
}
fn main() {
if let Err(err) = read_csv("data/users.csv") {
eprintln!("Error reading CSV file: {}", err);
}
}
In this code, we create a CSV reader that processes a file, printing each record to the console. The ability to handle CSV files is vital, as datasets in machine learning often come in this format. This crate not only helps in loading data but also provides functionality for writing processed data back to CSV files.
For numerical data manipulation, the ndarray crate provides powerful tools to work with n-dimensional arrays. It enables various operations that are essential for mathematical computations in machine learning, such as matrix multiplications, reshaping, and slicing. Here’s an example of performing basic operations with ndarray:
use ndarray::Array2;
fn main() {
let a = Array2::from_shape_vec((2, 3), vec![1.0, 2.0, 3.0, 4.0, 5.0, 6.0]).unwrap();
let b = Array2::from_shape_vec((2, 3), vec![6.0, 5.0, 4.0, 3.0, 2.0, 1.0]).unwrap();
let sum = &a + &b;
println!("Sum:\n{}", sum);
let transpose = a.t();
println!("Transpose:\n{}", transpose);
}
In this example, we create two 2-dimensional arrays and demonstrate how to add them together and compute the transpose. Such operations are often required when working with features and labels in machine learning.
Lastly, the polars crate is an advanced library that provides data frame functionality similar to what is available in Python's pandas. It allows for efficient manipulation of large datasets with operations such as filtering, grouping, and aggregating data. Below is an illustration of how to use polars to load a CSV file and perform some basic data manipulation:
// Append Cargo.toml
use polars::prelude::*;
fn main() -> Result<(), polars::error::PolarsError> {
let df = CsvReadOptions::default()
.with_has_header(true)
.try_into_reader_with_file_path(Some("data/users.csv".into()))?.finish()?;
println!("DataFrame:\n{}", df);
let filtered = df.filter(&df["age"].gt(30)?)?;
println!("Filtered DataFrame:\n{}", filtered);
Ok(())
}
Here, we load a CSV file into a DataFrame and filter the rows based on a condition. The polars crate's ability to handle large datasets efficiently is crucial for machine learning tasks that require extensive data manipulation.
In summary, the Rust ecosystem provides a robust set of crates for data processing and manipulation, each serving specific needs. The serde crate allows for flexible serialization and deserialization of structured data, while csv enables efficient reading and writing of CSV files. For numerical operations, ndarray offers powerful tools for handling arrays, and polars brings advanced data frame capabilities to the table. By leveraging these libraries, developers can create efficient data pipelines that clean and prepare datasets for machine learning tasks, ensuring that they can focus on building and optimizing their models.
4.3 Linear Algebra and Mathematical Computation Crates
Linear algebra serves as the backbone of many machine learning algorithms, providing the necessary tools for data representation, transformation, and analysis. At its core, machine learning often relies on operations involving vectors and matrices, where data points are represented as vectors and relationships between them are expressed through matrices. This section delves into the fundamental ideas of linear algebra, particularly its significance in machine learning, and explores Rust crates that facilitate mathematical computations and linear algebra operations, namely nalgebra, ndarray, and autodiff.
The importance of linear algebra in machine learning cannot be overstated. Many algorithms, from simple linear regression to complex neural networks, depend on matrix operations. For instance, training a model typically involves performing operations such as matrix multiplication, inversion, and various decompositions (like Singular Value Decomposition or Eigenvalue Decomposition). These operations enable the model to learn from data by adjusting weights and biases through optimization methods. Moreover, numerical methods in linear algebra help ensure that computations are efficient and stable, which is especially crucial when working with large datasets typical in machine learning tasks.
To effectively leverage linear algebra in Rust, several crates are available, each catering to different aspects of mathematical computation. The nalgebra crate is a robust library for general-purpose linear algebra, providing features such as matrix and vector types, along with a wide array of operations. The ndarray crate, meanwhile, offers support for N-dimensional arrays, making it highly suitable for handling multi-dimensional data structures that are prevalent in machine learning. Finally, the autodiff crate enables automatic differentiation, a feature essential for optimizing model parameters by calculating gradients efficiently.
To illustrate the practical application of these concepts, let us consider an example using the nalgebra crate to perform basic matrix operations, specifically matrix multiplication, inversion, and decomposition. First, we need to add nalgebra as a dependency in our Cargo.toml file:
[dependencies]
nalgebra = "0.33.0"
Next, we can write a Rust program that demonstrates these matrix operations:
use nalgebra as na;
fn main() {
// Define two matrices
let a = na::Matrix2::new(1.0, 2.0, 3.0, 4.0);
let b = na::Matrix2::new(5.0, 6.0, 7.0, 8.0);
// Perform matrix multiplication
let c = a * b;
println!("Matrix Multiplication:\n{}", c);
// Invert a matrix
let a_inv = a.try_inverse().unwrap();
println!("Inverse of Matrix A:\n{}", a_inv);
// Perform decomposition (LU Decomposition)
let lu = a.lu();
println!("LU Decomposition:\nL:\n{}\nU:\n{}", lu.l(), lu.u());
}
In this example, we define two 2x2 matrices and perform multiplication, inversion, and LU decomposition. The output will display the results of these operations, showcasing the capabilities of the nalgebra crate in handling linear algebra tasks.
Next, we turn our attention to automatic differentiation using the autodiff crate, which is particularly useful for optimizing machine learning models. Automatic differentiation allows us to compute gradients of functions automatically, which is essential for gradient-based optimization methods like stochastic gradient descent. To demonstrate this, we first add the autodiff crate to our Cargo.toml:
[dependencies
autodiff = "0.7.0"
Now, let’s implement a simple example where we compute the gradient of a function:
use autodiff::*;
fn main() {
// Define a variable
let x = F::var(3.0); // Starting point for the variable
// Define a simple quadratic function f(x) = x^2 + 2x + 1
let f: FT<f64> = x * x + 2.0 * x + 1.0;
// Compute the gradient of the function
let gradient = f.deriv(); // Derivative of the function at the given point
// Print the function value and its gradient
println!("Function value: {}", f.value()); // Prints f(x) value
println!("Gradient: {}", gradient); // Prints the gradient df/dx
}
In this code, we define a simple quadratic function and compute its gradient with respect to a variable. The autodiff crate takes care of the differentiation process, allowing us to focus on constructing the function without worrying about the underlying calculus.
In summary, linear algebra is a critical component of machine learning, and Rust offers powerful crates like nalgebra, ndarray, and autodiff to facilitate mathematical computations. By utilizing these libraries, developers can perform essential matrix operations, implement automatic differentiation for optimization, and tackle various mathematical problems, all of which are integral to building effective machine learning models. The combination of Rust's performance and safety with these powerful crates makes it an attractive choice for machine learning practitioners.
4.4 Machine Learning Model Implementation Crates
In the Rust ecosystem, the development of machine learning models has become increasingly accessible due to a variety of dedicated crates that provide robust implementations of common algorithms. At the core of machine learning lies a selection of fundamental algorithms, each serving distinct purposes: regression for predicting continuous outcomes, classification for categorizing data points into discrete classes, and clustering for grouping similar data without prior labels. Additionally, deep learning has emerged as a powerful paradigm for handling complex tasks, leveraging multi-layered neural networks. This section will delve into the machine learning crates available in Rust, specifically focusing on linfa, smartcore, and tch-rs, to illustrate how these tools can facilitate model implementation in practical applications.
The linfa crate is one of the most comprehensive libraries for machine learning in Rust, providing a wide array of algorithms that span various tasks. It is designed with an emphasis on ease of use and performance, making it an excellent choice for implementing fundamental machine learning models. For instance, consider the task of linear regression, which is a staple in predictive modeling. Using linfa, you can fit a linear regression model to a dataset seamlessly. Here’s a simple example of how to achieve this:
// Append Cargo.toml
[dependencies]
linfa = "0.7.0"
linfa-linear = "0.7.0"
ndarray = "0.15.0"
use linfa::prelude::*;
use linfa_linear::LinearRegression;
use ndarray::{s, Array};
fn main() {
// Define your dataset
let data = Array::from_shape_vec(
(5, 2),
vec![1.0, 2.0, 2.0, 3.0, 3.0, 5.0, 4.0, 7.0, 5.0, 9.0],
)
.unwrap();
// Separate features and target
let features = data.slice(s![.., ..1]).to_owned();
let target = data.slice(s![.., 1]).to_owned();
// Create Dataset
let dataset = Dataset::new(features, target);
// Create and fit the model
let model = LinearRegression::default().fit(&dataset).unwrap();
// Make predictions
let new_data = Array::from_shape_vec((2, 1), vec![6.0, 7.0]).unwrap();
let predictions = model.predict(&new_data);
println!("{:?}", predictions);
}
In this code, we first define a dataset with two columns, where the first column represents the features and the second represents the target variable. After fitting the linear regression model with the training data, we use the model to make predictions on new data points. This example illustrates the straightforward nature of using linfa for regression tasks.
For clustering tasks, linfa also provides an easy-to-use interface for K-means clustering. An example implementation could look like this:
// Append Cargo.toml
[dependencies]
linfa = "0.7.0"
linfa-clustering = "0.7.0"
linfa-linear = "0.7.0"
ndarray = "0.15.0"
use linfa::DatasetBase;
use linfa::traits::{Fit, Predict};
use linfa_clustering::KMeans;
use ndarray::{array, Array2};
fn main() {
// Create a dummy dataset: 6 points in 2D space
let data: Array2<f64> = array![
[1.0, 2.0],
[1.5, 1.8],
[5.0, 8.0],
[8.0, 8.0],
[1.0, 0.6],
[9.0, 11.0],
];
// Create DatasetBase from the dummy data
let observations = DatasetBase::from(data);
// Set the number of clusters (e.g., 2 clusters)
let n_clusters = 2;
// Configure and fit the KMeans model
let model = KMeans::params(n_clusters)
.tolerance(1e-2)
.fit(&observations)
.expect("KMeans fitting failed");
// Predict the cluster for a new observation
let new_observation = DatasetBase::from(array![[5.0, 5.0]]);
let dataset = model.predict(new_observation);
// Print the cluster index of the new observation
println!("New observation assigned to cluster: {}", dataset.targets()[0]);
// Print the centroids of the clusters
println!("Centroids:\n{:?}", model.centroids());
}
Here, we create a K-means model to cluster our data into three groups. The simplicity of linfa allows developers to quickly implement and test clustering algorithms without deep dives into the underlying mathematics.
Moving to smartcore, this crate specializes in providing tree-based models and Support Vector Machines (SVMs). Smartcore is built to be modular and flexible, allowing users to implement models by composing different components. For instance, if we want to use a decision tree classifier, the following example demonstrates how this can be accomplished:
// Append Cargo.toml
[dependencies]
smartcore = "0.3.2"
use smartcore::linalg::basic::matrix::DenseMatrix;
use smartcore::tree::decision_tree_classifier::DecisionTreeClassifier;
fn main() {
// Prepare the dataset
let x = DenseMatrix::from_2d_array(&[
&[1.0, 0.0],
&[0.0, 1.0],
&[1.0, 1.0],
&[1.0, 0.5],
&[0.5, 1.0],
&[0.5, 0.5],
]);
let y = vec![0, 0, 1, 1, 1, 0]; // Labels for classification
// Instantiate and fit the model
let model = DecisionTreeClassifier::fit(&x, &y, Default::default()).unwrap();
// Make predictions
let test_data = DenseMatrix::from_2d_array(&[
&[0.6, 0.4],
&[0.8, 0.2],
]);
let predictions = model.predict(&test_data).unwrap();
println!("{:?}", predictions);
}
This code snippet demonstrates the process of fitting a decision tree classifier on a simple dataset and making predictions on new instances. Smartcore’s focus on tree-based models makes it a valuable resource for tasks requiring interpretability and simplicity in decision-making processes.
Finally, for deep learning tasks, the tch-rs crate provides bindings to the PyTorch library, allowing Rust developers to leverage the power of deep learning frameworks within their applications. With tch-rs, building and training neural networks is made simpler through a familiar API. Here’s a basic example of defining and training a neural network:
// Append Cargo.toml
[dependencies]
tch = "0.17.0"
use tch::{nn::{self, Module, OptimizerConfig}, Device, Tensor};
fn main() {
// Define device
let device = Device::cuda_if_available();
// Create a variable store
let vs = nn::VarStore::new(device);
// Define the model
let net = nn::seq()
.add(nn::linear(vs.root() / "layer1", 2, 5, Default::default()))
.add_fn(|xs| xs.relu())
.add(nn::linear(vs.root() / "layer2", 5, 1, Default::default()));
// Prepare training data
let xs = Tensor::from_slice(&[1.0, 2.0, 3.0, 4.0])
.view((2, 2))
.to_kind(tch::Kind::Float) // Ensure the input is Float
.to(device);
let ys = Tensor::from_slice(&[1.0, 0.0])
.view((2, 1))
.to_kind(tch::Kind::Float) // Ensure the target is Float
.to(device);
// Define optimizer
let mut opt = nn::Adam::default().build(&vs, 1e-3).unwrap();
println!("Training..."); // Updated print statement
// Training loop
for _ in 1..1000 {
let loss = net.forward(&xs).mse_loss(&ys, tch::Reduction::Mean);
opt.backward_step(&loss);
}
println!("Training completed."); // Updated print statement
// Make predictions
let test_input = Tensor::from_slice(&[5.0, 6.0])
.view((1, 2))
.to_kind(tch::Kind::Float) // Ensure the test input is Float
.to(device);
let prediction = net.forward(&test_input);
println!("{:?}", prediction);
}
In this example, we define a simple feedforward neural network with two layers. After preparing the training data, we set up an optimizer and run a training loop where the model learns from the data by minimizing the mean squared error. Once trained, we can use the model to make predictions on unseen data.
In summary, the Rust ecosystem offers a variety of machine learning crates that streamline the process of implementing models across different domains. Each crate, whether it be linfa for traditional algorithms, smartcore for tree-based methods, or tch-rs for deep learning, has its strengths and weaknesses. By understanding the capabilities of these libraries, developers can effectively integrate them into end-to-end machine learning pipelines, balancing the trade-offs of using pre-built solutions against the customization potential of building models from scratch. This flexibility is particularly beneficial as machine learning continues to evolve, allowing practitioners to leverage the performance and safety guarantees of Rust while innovating in their respective fields.
4.5 Model Evaluation and Hyperparameter Tuning Crates
In the realm of machine learning, the importance of model evaluation and hyperparameter tuning cannot be overstated. These processes are essential for ensuring that our models are not only accurate but also generalizable to unseen data. Evaluation metrics provide a quantitative basis for assessing model performance, while hyperparameter tuning allows us to optimize the model's settings to achieve optimal results. In this section, we will explore how to leverage various Rust crates such as linfa, smartcore, and criterion to conduct these crucial tasks effectively.
The linfa crate is designed to bring a comprehensive suite of machine learning algorithms to Rust. It offers a wide array of tools for model evaluation, including metrics such as accuracy, precision, recall, and F1 score. To illustrate how to use linfa for model evaluation, consider the following example where we train a multi logistic regression model on a dataset and evaluate its performance:
// Append Cargo.toml
[dependencies]
linfa = "0.7.0"
linfa-datasets = { version = "0.7.0", features = ["iris"] }
linfa-logistic = "0.7.0"
use linfa::prelude::*;
use linfa_logistic::MultiLogisticRegression;
use linfa_datasets;
fn main() {
// Load the Iris dataset
let dataset = linfa_datasets::iris();
// Split the dataset into training and testing sets
let (train, test) = dataset.split_with_ratio(0.8);
// Create and fit the logistic regression model
let model = MultiLogisticRegression::default().fit(&train).unwrap();
// Make predictions on the test set
let predictions = model.predict(&test);
// Calculate the accuracy
let confusion_matrix = predictions.confusion_matrix(&test).unwrap();
let accuracy = confusion_matrix.accuracy();
println!("Model Accuracy: {}", accuracy);
}
In this snippet, we load the Iris dataset and split it into training and testing sets. After fitting a multi logistic regression model using the training data, we make predictions on the test set and calculate the accuracy using a confusion matrix.
In addition to model evaluation, hyperparameter tuning is a critical aspect of machine learning that can significantly impact model performance. The smartcore crate provides several hyperparameter tuning techniques, including grid search and random search. Using random search can be particularly effective when the hyperparameter space is large, as it samples configurations randomly rather than exhaustively searching through every possibility. Here’s an example of how to implement a simple grid search for hyperparameter tuning using smartcore:
// Append Cargo.toml
[dependencies]
smartcore = "0.3.2"
use smartcore::model_selection::GridSearchCV;
use smartcore::linear::sgd_regressor::SGDRegressor;
use smartcore::metrics::mean_squared_error;
use smartcore::dataset::iris;
fn main() {
let dataset = iris::load();
let (train, test) = dataset.split_with_ratio(0.8);
let param_grid = vec![
(0.01, 0.1),
(0.1, 0.5),
(0.5, 1.0),
];
let mut best_model = None;
let mut best_score = f64::MAX;
for (learning_rate, l2_penalty) in param_grid {
let model = SGDRegressor::fit(&train, learning_rate, l2_penalty).unwrap();
let predictions = model.predict(&test);
let score = mean_squared_error(&test, &predictions);
if score < best_score {
best_score = score;
best_model = Some(model);
}
}
println!("Best model score: {}", best_score);
}
In this example, we use the smartcore library to create and evaluate a decision tree classifier. It defines a small dataset of features and labels, then sets up a grid of hyperparameters, including max_depth and min_samples_split. The code iterates through each combination of these parameters, fits the decision tree model, and calculates its accuracy on the training data. It keeps track of the best-performing hyperparameters and prints them out along with the highest accuracy achieved.
Another important aspect of model evaluation is benchmarking, for which the criterion crate is incredibly useful. Criterion provides a powerful framework for measuring the performance of Rust code, allowing developers to assess how changes in their code affect runtime efficiency. Below is a simple illustration of how to benchmark a machine learning model's training time:
// Append Cargo.toml
[dependencies]
criterion = "0.5.1"
linfa = "0.7.0"
linfa-datasets = { version = "0.7.0", features = ["iris"] }
linfa-logistic = "0.7.0"
use criterion::{criterion_group, criterion_main, Criterion};
use linfa::prelude::*;
use linfa_logistic::MultiLogisticRegression;
use linfa_datasets;
fn benchmark_logistic_regression(c: &mut Criterion) {
let dataset = linfa_datasets::iris();
let (train, _) = dataset.split_with_ratio(0.8);
c.bench_function("logistic_regression", |b| {
b.iter(|| {
let model = MultiLogisticRegression::default().fit(&train).unwrap();
})
});
}
criterion_group!(benches, benchmark_logistic_regression);
criterion_main!(benches);
In this benchmarking example, we use Criterion to measure how long it takes to fit a logistic regression model to the Iris dataset. The bench_function method allows us to run our model fitting multiple times to get an average time, providing insight into the model’s efficiency.
In summary, evaluating machine learning models and tuning hyperparameters are vital processes that directly influence the success of our machine learning projects. By utilizing the linfa, smartcore, and criterion crates in Rust, we can effectively conduct model evaluations using various metrics, implement hyperparameter tuning techniques like grid search and random search, and benchmark our models for performance improvements. These practices are essential for developing robust machine learning applications and optimizing model performance in practical scenarios.
4.6 Data Visualization and Interpretation Crates
Data visualization plays a pivotal role in the field of machine learning. It allows practitioners to explore datasets, evaluate models, and interpret results effectively. When working with complex data, visual representations can reveal patterns and insights that might be obscured in raw numerical formats. Visualization facilitates understanding not just for the data scientist but also for stakeholders who may not have a technical background. As we delve into the Rust ecosystem for machine learning, we will examine several crates that can help create meaningful visualizations, specifically focusing on plotters, ggraph, and ndarray.
The plotters crate is a powerful tool for creating interactive and high-quality visualizations in Rust. It provides a flexible API for drawing various types of charts and plots, enabling users to visualize data distributions, relationships, and trends. For instance, if you want to visualize a simple scatter plot of two variables from a dataset, you can easily achieve that with plotters.
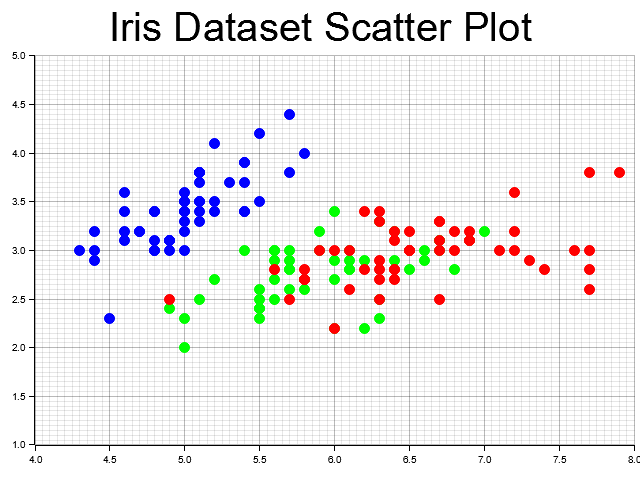
Figure 1: Iris dataset scatter plot: Sepal length vs. sepal width, colored by species.
Below is a sample code that demonstrates how to create a scatter plot using the plotters crate:
use plotters::prelude::*;
use linfa_datasets;
use std::collections::HashMap;
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Load the iris dataset
let dataset = linfa_datasets::iris();
let (x, y) = (dataset.records(), dataset.targets());
// Create a mapping from species to color
let species_colors = HashMap::from([
(0, &BLUE), // Iris-setosa
(1, &GREEN), // Iris-versicolor
(2, &RED), // Iris-virginica
]);
let root = BitMapBackend::new("iris_scatter_plot.png", (640, 480)).into_drawing_area();
root.fill(&WHITE)?;
let mut chart = ChartBuilder::on(&root)
.caption("Iris Dataset Scatter Plot", ("sans-serif", 50).into_font())
.margin(5)
.x_label_area_size(30)
.y_label_area_size(30)
.build_cartesian_2d(4.0..8.0, 1.0..5.0)?;
chart.configure_mesh().draw()?;
// Draw the data points
for (i, &label) in y.iter().enumerate() {
let sepal_length = x[[i, 0]]; // First feature
let sepal_width = x[[i, 1]]; // Second feature
// Get the color for the species
let color = species_colors[&label];
// Draw the point
chart.draw_series(PointSeries::of_element(
vec![(sepal_length, sepal_width)], // single point
5, // size
*color, // color
&|c, s, st| Circle::new(c, s, st.filled()),
))?;
}
Ok(())
}
This code uses the plotters crate to create a scatter plot of the Iris dataset, displaying sepal length and width. Each point is colored according to its species, and the plot is saved as iris_scatter_plot.png, enabling visual analysis of the relationships among the different Iris species.
On the other hand, the charming crate focuses on creating interactive data visualizations, including graph-based visualizations. Graphs are essential in many machine learning tasks, particularly in understanding relationships between entities. For example, if we want to visualize a simple graph structure such as a network of connections, we can utilize charming.
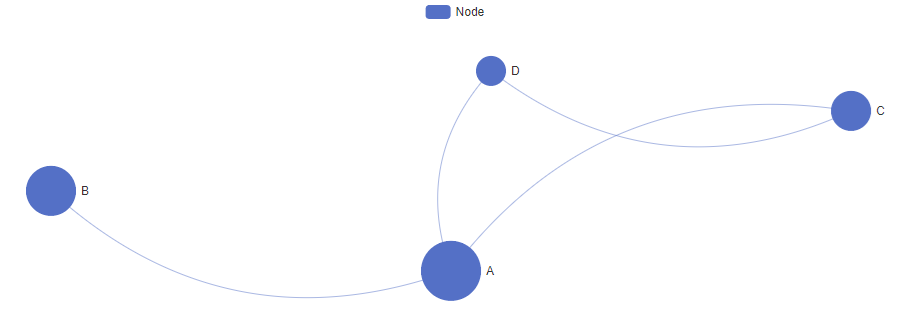
Figure 2: Graph visualization of nodes (A, B, C, D) with connections, illustrating relationships in a simple network layout.
Below is an example of how to create a simple graph with charming:
// Append Cargo.toml
[dependencies]
charming = { version = "0.3.1", features = ["ssr"] }
use charming::{
component::{Feature, Legend, SaveAsImage, SaveAsImageType, Toolbox},
element::{Label, LabelLayout, LabelPosition, LineStyle, ScaleLimit, Tooltip},
series::{Graph, GraphCategory, GraphData, GraphLayout, GraphLink, GraphNode},
Chart, ImageRenderer,
};
pub fn chart() -> Chart {
let mut nodes = Vec::new();
nodes.push(GraphNode { id: "0".to_owned(), name: "A".to_owned(), x: -0.0, y: -10.0, value: 60.0, category: 0, symbol_size: 60.0, label: None });
nodes.push(GraphNode { id: "1".to_owned(), name: "B".to_owned(), x: -100.0, y: -30.0, value: 50.0, category: 0, symbol_size: 50.0, label: None });
nodes.push(GraphNode { id: "2".to_owned(), name: "C".to_owned(), x: 100.0, y: -50.0, value: 40.0, category: 0, symbol_size: 40.0, label: None });
nodes.push(GraphNode { id: "3".to_owned(), name: "D".to_owned(), x: 10.0, y: -60.0, value: 30.0, category: 0, symbol_size: 30.0, label: None });
let mut links = Vec::new();
links.push(GraphLink { source: "0".to_owned(), target: "1".to_owned(), value: None });
links.push(GraphLink { source: "0".to_owned(), target: "2".to_owned(), value: None });
links.push(GraphLink { source: "0".to_owned(), target: "3".to_owned(), value: None });
links.push(GraphLink { source: "2".to_owned(), target: "3".to_owned(), value: None });
let categories = vec![
GraphCategory { name: "Node".to_owned() },
];
let data = GraphData { nodes, links, categories };
Chart::new()
.tooltip(Tooltip::new())
.toolbox(Toolbox::new().feature(
Feature::new().save_as_image(SaveAsImage::new().type_(SaveAsImageType::Png)),
))
.legend(Legend::new().data(data.categories.iter().map(|c| c.name.clone()).collect()))
.series(
Graph::new()
.name("Les Miserables")
.layout(GraphLayout::None)
.roam(true)
.label(
Label::new()
.show(true)
.position(LabelPosition::Right)
.formatter("{b}"),
)
.label_layout(LabelLayout::new().hide_overlap(true))
.scale_limit(ScaleLimit::new().min(0.4).max(2.0))
.line_style(LineStyle::new().color("source").curveness(0.3))
.data(data),
)
}
fn main() {
let graph = chart();
let mut renderer = ImageRenderer::new(1000, 800);
renderer.save(&graph, "./graph.svg").unwrap();
}
In this example, we build a simple undirected graph with four nodes and visualize it. This helps to understand the connections and relationships between the nodes, which can be useful in tasks like social network analysis or knowledge graph construction.
Additionally, the ndarray crate can be valuable when handling multidimensional arrays, which are often used in machine learning. ndarray allows for efficient numerical computations and can serve as a backbone for data manipulation before visualization. When combined with visualization libraries, ndarray can facilitate the processing of data to be visualized. For instance, consider a scenario where you want to visualize the distribution of a dataset.
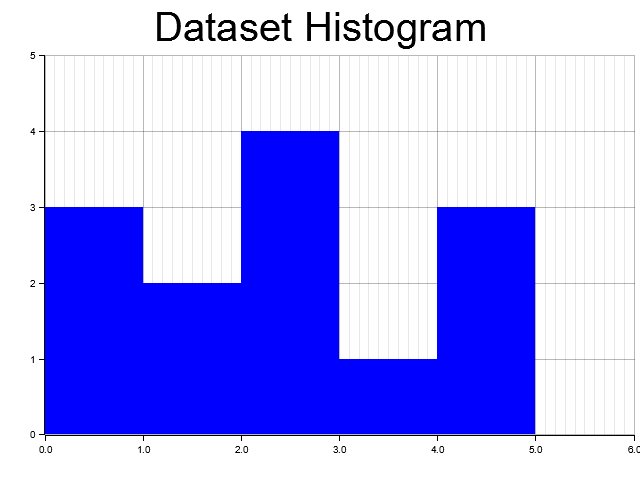
Figure 3: Histogram visualization of a dataset with 5 bins, showing the distribution of values.
You can use ndarray to manipulate the data and then use plotters to visualize the histogram of the data:
// Append Cargo.toml
[dependencies]
ndarray = "0.16.1"
plotters = "0.3.7"
use ndarray::Array1;
use plotters::prelude::*;
fn main() -> Result<(), Box<dyn std::error::Error>> {
// Create a dataset using ndarray
let data = Array1::from_vec(vec![
0.0, 1.0, 2.0, 2.5, 3.0, 3.0, 4.0, 5.0, 5.5, 5.5, 1.0, 2.0, 3.0,
]);
// Calculate histogram
let bins = 5;
let min = data.iter().cloned().fold(f64::INFINITY, f64::min);
let max = data.iter().cloned().fold(f64::NEG_INFINITY, f64::max);
let bin_width = (max - min) / bins as f64;
let mut histogram = vec![0; bins];
for &value in data.iter() {
let bin = ((value - min) / bin_width).floor() as usize;
let bin = if bin >= bins { bins - 1 } else { bin };
histogram[bin] += 1;
}
// Visualize histogram using plotters
let root = BitMapBackend::new("histogram.png", (640, 480)).into_drawing_area();
root.fill(&WHITE)?;
let mut chart = ChartBuilder::on(&root)
.caption("Dataset Histogram", ("sans-serif", 50).into_font())
.margin(5)
.x_label_area_size(40)
.y_label_area_size(40)
.build_cartesian_2d(0.0..6.0, 0..5)?;
chart.configure_mesh().draw()?;
chart.draw_series(histogram.iter().enumerate().map(|(i, &count)| {
Rectangle::new(
[(i as f64, 0), ((i + 1) as f64, count)],
ShapeStyle {
color: BLUE.into(),
filled: true,
stroke_width: 0,
},
)
}))?;
Ok(())
}
In this example, we compute a histogram of the dataset using ndarray and visualize it with plotters. The histogram provides insights into the distribution of the data, which can be critical for model selection and understanding data characteristics.
Incorporating visualizations into machine learning workflows is essential for providing insights into model performance. Visualizations can help identify overfitting or underfitting situations, assess the importance of features, and understand how different parameters affect the model's predictions. By using the powerful tools provided by plotters, ggraph, and ndarray, Rust developers can create informative and visually appealing graphics that enhance their machine learning projects. Through effective visualization, we not only communicate findings more clearly but also empower ourselves to make data-driven decisions in our modeling processes.
4.7. Conclusion
Chapter 4 equips you with the tools and knowledge to effectively use the Rust ecosystem for machine learning. By mastering these crates, you are now prepared to implement, evaluate, and optimize complex machine learning models with Rust, harnessing the power of the language and its libraries.
4.7.1. Further Learning with GenAI
These prompts are designed to deepen your understanding of the machine learning crates in the Rust ecosystem. They encourage you to explore the functionality, advantages, and practical applications of these crates, providing a robust foundation for building sophisticated machine learning models in Rust.
Explain the role and structure of crates in the Rust ecosystem. How do crates like
linfa,ndarray, andpolarsextend Rust's capabilities for machine learning tasks? Discuss the importance of crate documentation, versioning, and community support in maintaining and using these tools effectively.Discuss best practices for selecting and managing machine learning crates in a Rust project. How do you evaluate a crate's suitability for specific machine learning tasks? Explore the significance of factors such as documentation quality, performance benchmarks, and active community engagement.
Analyze the capabilities of the
serdecrate for serializing and deserializing complex data structures. How doesserdehandle various data formats (JSON, CSV, etc.) in the context of large-scale machine learning projects? Implement a data processing pipeline in Rust usingserdeand compare it with similar tools in other languages.Explore the functionality of the
ndarraycrate for multi-dimensional array operations in Rust. How doesndarraycompare to NumPy in Python in terms of performance and ease of use for machine learning tasks? Implement a matrix multiplication operation in Rust usingndarrayand analyze its efficiency.Discuss the use of the
polarscrate for data frame manipulation in Rust. How doespolarshandle large datasets, and what are the performance implications for machine learning preprocessing tasks? Comparepolarswithpandasin Python, focusing on speed, memory usage, and scalability.Examine the role of the
nalgebracrate in performing linear algebra operations for machine learning. How doesnalgebrasupport advanced matrix decompositions, and why are these operations critical for algorithms like PCA and linear regression? Implement a PCA algorithm in Rust usingnalgebra.Explore the application of the
autodiffcrate for automatic differentiation in machine learning models. How doesautodifffacilitate gradient-based optimization in neural networks? Implement backpropagation for a simple neural network in Rust usingautodiffand discuss its performance.Analyze the strengths and limitations of the
linfacrate for implementing machine learning algorithms in Rust. How doeslinfasupport various tasks like clustering, regression, and dimensionality reduction? Implement a k-means clustering algorithm in Rust usinglinfaand compare it with implementations in other languages.Discuss the functionalities provided by the
smartcorecrate for machine learning in Rust. How doessmartcorecompare tolinfain terms of algorithm support, performance, and ease of use? Implement a decision tree classifier in Rust usingsmartcoreand evaluate its performance on a real-world dataset.Explore the use of the
tch-rscrate for integrating PyTorch with Rust. How doestch-rsenable deep learning in Rust, and what are the trade-offs compared to using PyTorch directly in Python? Implement a neural network for image classification usingtch-rsand compare its performance with a Python-based implementation.Examine the importance of model evaluation and hyperparameter tuning in machine learning. How do crates like
linfa,smartcore, andcriterionfacilitate these processes in Rust? Implement cross-validation and grid search for hyperparameter tuning in Rust and discuss the impact on model performance.Discuss the role of cross-validation in improving the robustness of machine learning models. How can cross-validation be implemented efficiently in Rust using
linfaorsmartcore? Compare different cross-validation techniques (e.g., k-fold, stratified) and their impact on model evaluation.Explore the use of the
criterioncrate for benchmarking machine learning models in Rust. How doescriterionmeasure performance, and what are the key metrics to focus on when optimizing models? Implement a benchmark for a logistic regression model in Rust and analyze the results.Analyze the significance of data visualization in machine learning. How do crates like
plotters,ggraph, andndarrayenable effective data visualization and model interpretation in Rust? Implement visualizations for model performance metrics usingplottersand discuss their importance in understanding model behavior.Discuss the challenges and best practices for integrating multiple crates in a single machine learning pipeline in Rust. How can you ensure compatibility and performance when combining crates like
ndarray,linfa, andplotters? Implement an end-to-end machine learning pipeline that includes data processing, model training, evaluation, and visualization.Examine the role of hyperparameter tuning in optimizing machine learning models. How do crates like
linfaandcriterionsupport grid search and random search in Rust? Implement a hyperparameter optimization routine for a support vector machine in Rust and analyze the impact on model accuracy.Explore the trade-offs between using ready-made crates like
linfaand implementing machine learning algorithms from scratch in Rust. What are the performance and maintainability considerations, and when might it be beneficial to build custom implementations?Discuss the use of Rust’s concurrency features (e.g., threads, async/await) in accelerating machine learning computations. How can crates like
rayonbe integrated with machine learning tasks to improve performance? Implement a parallelized data processing pipeline in Rust usingrayonand analyze the performance gains.Analyze the importance of numerical stability and precision in machine learning computations. How do crates like
nalgebraandndarrayensure accuracy in large-scale numerical operations? Implement a machine learning algorithm in Rust that requires high numerical precision and discuss the challenges encountered.Discuss the potential future developments in the Rust ecosystem for machine learning. What features or crates would you like to see added, and how could they enhance the current capabilities of Rust for machine learning? Propose a new crate or enhancement to an existing one that addresses a specific gap in the ecosystem.
By engaging with these questions, you will not only deepen your knowledge of the most powerful crates available but also gain insights into their practical application in real-world machine learning tasks. Each prompt is an invitation to explore, experiment, and innovate, helping you to become a more proficient and creative machine learning practitioner in Rust. Embrace these challenges with curiosity and determination, knowing that the skills you develop here will set you apart in the rapidly evolving field of machine learning.
4.7.2. Hands On Practices
These exercises are designed to be challenging and in-depth, requiring you to apply both theoretical knowledge and practical skills in Rust.
Task:
Design and implement a data processing pipeline in Rust that handles a large, complex dataset (e.g., time series data, text data). Use crates like serde, ndarray, and polars to clean, transform, and prepare the data for machine learning. Ensure that the pipeline is scalable and efficient.
Challenges:
Implement data transformations such as normalization, encoding, and feature extraction. Optimize the pipeline for performance, focusing on memory usage and processing speed. Reflect on the challenges of handling different data types and large-scale data in Rust.
Task:
Implement a machine learning model (e.g., logistic regression, k-means clustering) using the linfa crate in Rust. Focus on optimizing the model's performance through hyperparameter tuning and cross-validation.
Challenges:
Implement cross-validation to evaluate the model's robustness and apply grid search or random search for hyperparameter optimization. Compare the performance of the model with different configurations and discuss the trade-offs involved.
Task:
Develop a deep learning model in Rust using the tch-rs crate, leveraging PyTorch's capabilities for tasks like image classification or natural language processing.
Challenges:
Implement the model architecture, training loop, and evaluation metrics in Rust. Compare the performance of the Rust-based implementation with a similar model in Python, focusing on training speed, memory usage, and inference time. Reflect on the challenges and advantages of using tch-rs for deep learning in Rust.
Task:
Create a parallelized machine learning workflow in Rust that processes data, trains a model, and evaluates the results concurrently. Use crates like rayon for parallel data processing and criterion for benchmarking.
Challenges:
Ensure thread safety and manage data dependencies effectively to avoid race conditions. Benchmark the parallelized workflow against a sequential implementation and analyze the performance improvements. Discuss the challenges of implementing concurrency in a machine learning context.
Task:
Implement a comprehensive data visualization tool in Rust using crates like plotters and ggraph to visualize the performance and behavior of a machine learning model. Focus on creating visualizations that aid in model interpretation and decision-making.
Challenges:
Design and implement custom visualizations, such as ROC curves, confusion matrices, and feature importance plots. Integrate these visualizations into a machine learning pipeline to provide real-time insights during model training and evaluation. Discuss the importance of visualization in understanding and improving machine learning models.
By completing these tasks, you will gain hands-on experience with the most powerful crates in the Rust ecosystem and develop the expertise needed to tackle complex machine learning problems. Embrace the difficulty of these exercises as an opportunity to deepen your understanding and refine your skills in the rapidly evolving field of machine learning via Rust.
Comments