Chapter 21
Deploying Machine Learning Models
"The measure of intelligence is the ability to change." — Albert Einstein
Chapter 21 of MLVR provides a comprehensive guide to deploying machine learning models into production environments, a crucial step in realizing the value of machine learning systems. The chapter begins by introducing the fundamental concepts of model deployment, including the differences between development and production environments and the challenges involved in this transition. It then delves into the infrastructure required for deployment, discussing cloud services, containerization, and the tools needed to deploy models at scale. The chapter covers model serving, focusing on designing robust APIs for real-time predictions, and explores CI/CD practices, highlighting the importance of automated workflows in maintaining reliable systems. Monitoring, logging, and security are also addressed, providing readers with the knowledge to maintain and protect deployed models. Finally, the chapter discusses scaling, load balancing, and A/B testing, offering strategies for optimizing performance and validating model improvements in production. By the end of this chapter, readers will have a deep understanding of how to deploy, monitor, and scale machine learning models using Rust.
21.1. Introduction to Model Deployment
Model deployment refers to the process of making a trained machine learning model available for use in a production environment. This is a crucial step in the machine learning pipeline, as it transforms a theoretical model, which has been trained and validated in a controlled environment, into a practical application that can deliver value to end-users. The importance of model deployment cannot be overstated; it bridges the gap between data science and real-world application, enabling organizations to harness the predictive power of their models in operational settings.
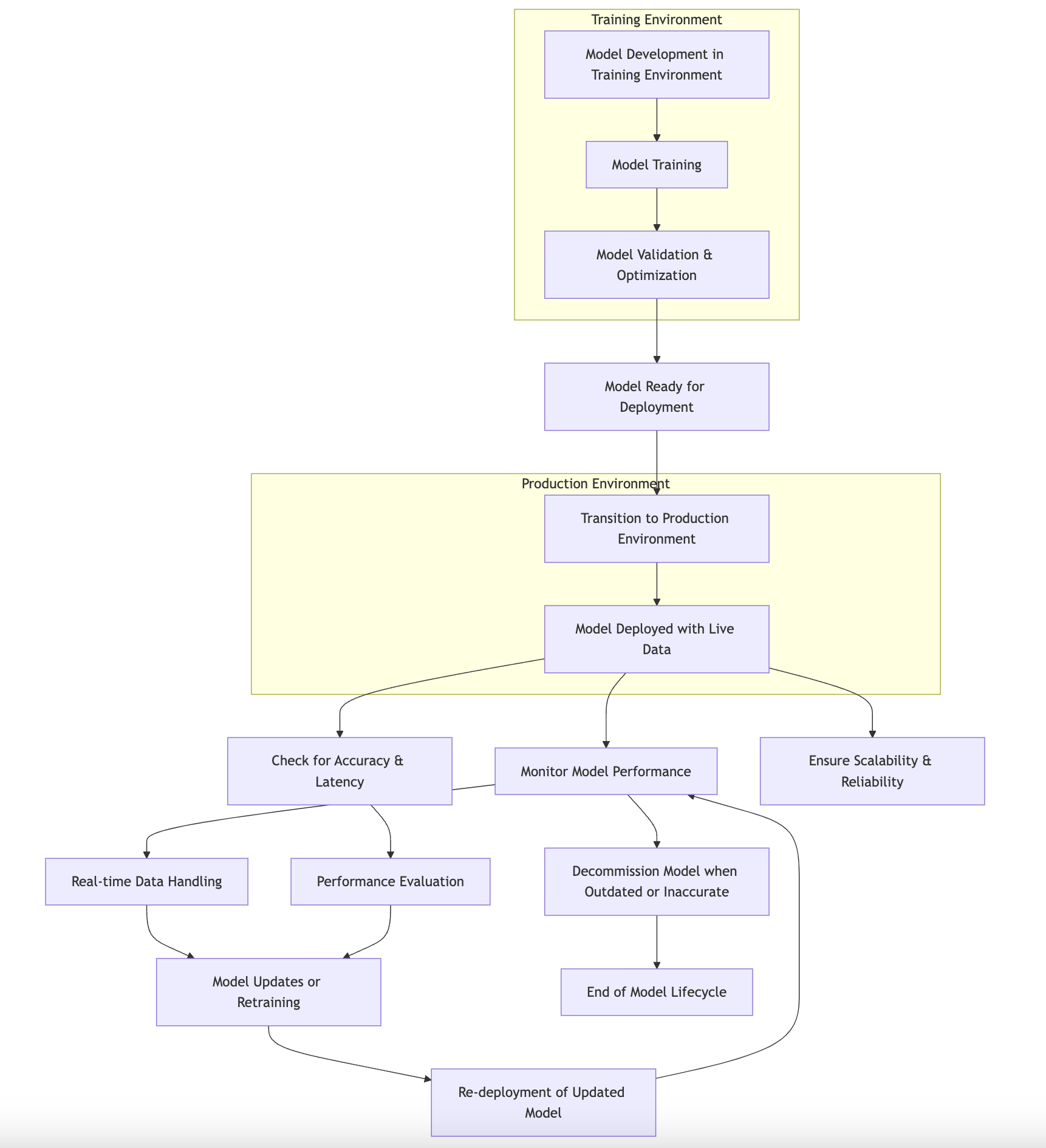
Figure 1: ML model deployment process.
When we talk about deployment, it is essential to differentiate between training and production environments. The training environment is where data scientists develop models, often using extensive datasets and complex computational resources. Here, the focus is primarily on experimentation, optimization, and evaluation of the model's performance. In contrast, the production environment is where the model interacts with live data and users, often under strict performance constraints. In production, the model must not only maintain high accuracy but also operate efficiently, responding to requests quickly and reliably. The lifecycle of deployed models involves several stages: initial deployment, monitoring, updating, and, when necessary, decommissioning. Each of these stages requires careful consideration of how the model will perform under real-world conditions.
Transitioning from a development to a production environment presents a range of challenges that developers must navigate carefully. Scalability becomes a significant concern, as models that perform well on a small scale may struggle to handle larger, more dynamic datasets in production. Latency is another critical factor; users expect models to respond in real-time or near-real-time, which can be difficult to achieve in a production setting. Furthermore, reliability is paramount—any downtime or performance degradation can lead to a poor user experience or even financial loss for a business. Thus, understanding these challenges is essential for anyone looking to deploy machine learning models effectively.
To illustrate the practical aspects of deploying a machine learning model using Rust, we can start by implementing a simple deployment pipeline. For our example, we will deploy a basic linear regression model trained on a dataset, such as predicting house prices based on various features. We'll utilize the rust-bert library for our model and warp for creating a simple web server that will serve predictions.
First, we need to set up a Rust project and include necessary dependencies in our Cargo.toml:
[dependencies]
ndarray = "0.15"
rand = "0.8"
Next, we can create a simple linear regression model. For simplicity, we'll generate some synthetic data for training:
use ndarray::Array2;
// Removed unused imports
// use ndarray_rand::RandomExt;
// use ndarray_rand::rand_distr::Uniform;
fn generate_data(samples: usize) -> (Array2<f64>, Array2<f64>) {
let x = Array2::from_shape_fn((samples, 1), |_| rand::random::<f64>() * 10.0);
let noise = Array2::from_shape_fn((samples, 1), |_| rand::random::<f64>() * 2.0 - 1.0); // Uniformly between -1.0 and 1.0
let y = &x * 2.0 + 1.0 + noise; // y = 2x + 1 + noise
(x, y)
}
fn main() {
let (_x_train, _y_train) = generate_data(100); // Prefixing with underscores to suppress warnings
// Here you would typically train your model using the generated data.
println!("Training data generated.");
}
Once we have our model trained, we need to set up a web server to serve predictions. Using the warp framework, we can create a simple API endpoint that accepts input data and returns predictions. Below is a basic implementation of the web server:
use warp::Filter;
#[tokio::main]
async fn main() {
let predict = warp::path!("predict" / f64)
.map(|input: f64| {
// Here we would typically use our trained model to make a prediction.
let prediction = 2.0 * input + 1.0; // Placeholder for the model prediction.
warp::reply::json(&prediction)
});
warp::serve(predict).run(([127, 0, 0, 1], 3030)).await;
}
In this example, we created a simple web server that listens for GET requests on the /predict/{input} endpoint. When a request is received, it takes a floating-point number as input, simulates a model prediction (in this case, a simple linear equation), and returns the result as a JSON response.
This straightforward implementation serves to illustrate how you can deploy a basic machine learning model using Rust. In more complex scenarios, you might consider additional features such as model versioning, load balancing, and health checks to ensure reliability and performance in a production environment. Deployment scenarios can vary widely, from cloud-based solutions to edge computing, depending on the requirements of the application and the infrastructure available.
In conclusion, deploying machine learning models is a multifaceted process that requires careful planning and execution. By understanding the fundamental ideas of model deployment, the challenges associated with moving to a production environment, and the practical steps involved in implementing a deployment pipeline in Rust, developers can successfully bring their models to life, delivering valuable insights and predictions to users in real-time.
21.2. Infrastructure for Model Deployment
Deploying machine learning models is a critical step in the machine learning lifecycle, transforming a trained model into a usable application that can serve predictions in real time. To accomplish this, it is essential to understand the infrastructure requirements that support the deployment of such models effectively. The infrastructure encompasses not only the hardware and software resources but also the operational tools and technologies that facilitate the deployment process.
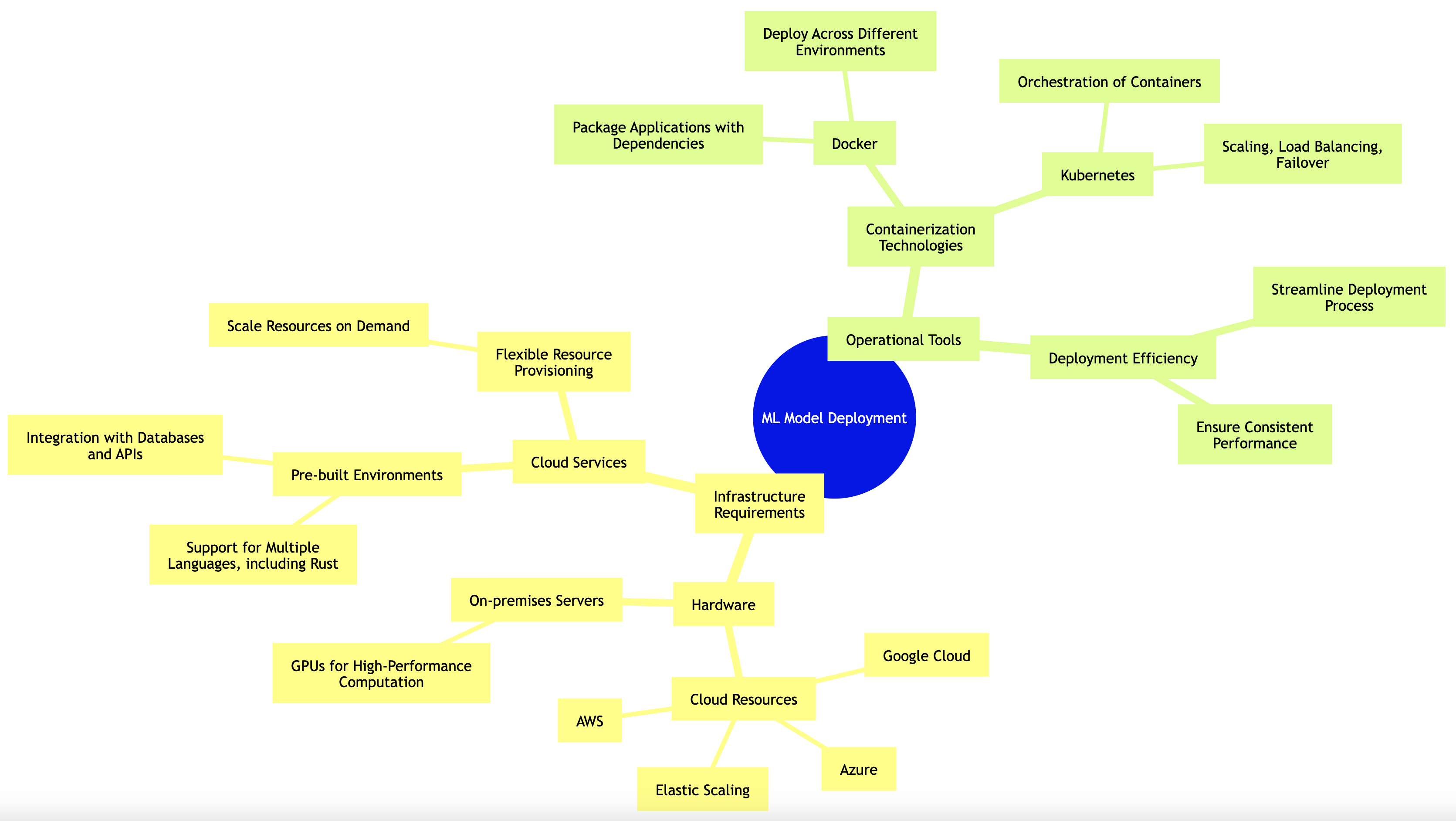
Figure 2: Infrastructure and process complexity of ML Model deployment.
At its core, the infrastructure for deploying machine learning models can be categorized into several components. First, there is the hardware aspect, which includes the physical servers or cloud resources that will host the application. Depending on the scale of your application, you may choose powerful on-premises servers equipped with GPUs for high-performance computation or opt for cloud services that provide flexible resources based on demand. Cloud providers such as AWS, Google Cloud, and Azure offer scalable computing resources that can be provisioned as needed, allowing for elastic scaling of machine learning models.
In addition to hardware, cloud services also provide numerous tools and services that streamline the deployment process. For instance, cloud-based machine learning platforms often come with pre-built environments that support various programming languages, including Rust, and provide easy integration with other services such as databases and APIs. Understanding how to leverage these services can significantly enhance the deployment process, making it more efficient and manageable.
Containerization technologies, such as Docker, play a pivotal role in modern deployment strategies. Docker allows developers to package applications and their dependencies into containers, which can be easily deployed across different environments without worrying about compatibility issues. This encapsulation ensures that the machine learning model runs consistently regardless of where it is deployed. Furthermore, tools like Kubernetes can orchestrate these containers, managing scaling, load balancing, and failover, thereby simplifying the deployment of containerized applications at scale.
To illustrate the practical aspects of setting up a deployment environment using Rust, Docker, and Kubernetes, consider the following scenario where we create a simple Rust-based machine learning model that we want to deploy. First, we need to ensure that we have Docker installed on our machine. The first step is to create a Dockerfile that describes how our Rust application will be built and run inside a container. Here’s an example Dockerfile for our Rust project:
# Use the official Rust image as the base image
FROM rust:1.70
# Set the working directory inside the container
WORKDIR /usr/src/YourAppName
# Copy the Cargo.toml and Cargo.lock files
COPY Cargo.toml Cargo.lock ./
# Copy the source code and build the application
COPY ./src ./src
# Build the application
RUN cargo build --release
# Specify the command to run the application
CMD ["./target/release/YourAppName"]
This Dockerfile first sets up the Rust environment, copies the necessary files, and builds the application. Once the Dockerfile is ready, we can build the Docker image using the following command:
docker build -t rust-ml-model .
After the Docker image is created, we can run it locally to test its functionality:
docker run -p 8080:8080 rust-ml-model
At this point, our Rust-based machine learning model is running inside a Docker container. The next step is to deploy this containerized application to a Kubernetes cluster. To do this, we need to create a Kubernetes Deployment manifest that specifies how to deploy our application. Here's a basic example of a deployment YAML file:
apiVersion: apps/v1
kind: Deployment
metadata:
name: rust-ml-model-deployment
spec:
replicas: 3
selector:
matchLabels:
app: rust-ml-model
template:
metadata:
labels:
app: rust-ml-model
spec:
containers:
- name: rust-ml-container
image: rust-ml-model:latest
ports:
- containerPort: 8080
This manifest defines a deployment with three replicas of our Rust application, ensuring high availability and load balancing. We can apply this deployment to the Kubernetes cluster using the following command:
kubectl apply -f deployment.yaml
Once the deployment is successful, we can expose our application using a Kubernetes Service, which provides a stable endpoint for accessing our Rust machine learning model:
apiVersion: v1
kind: Service
metadata:
name: rust-ml-service
spec:
selector:
app: rust-ml-model
ports:
- protocol: TCP
port: 80
targetPort: 8080
type: LoadBalancer
By applying this service configuration, Kubernetes will create a load balancer that routes traffic to our deployed Rust application. This setup allows users to access the model's predictions via a simple HTTP request.
In summary, deploying machine learning models requires a solid understanding of the infrastructure components involved, including hardware specifications, cloud services, and containerization technologies. By leveraging tools such as Docker and Kubernetes, developers can create scalable, maintainable, and efficient deployment environments for their Rust-based machine learning models. This not only simplifies the deployment process but also ensures that the models can be accessed reliably in production, ultimately enabling businesses to realize the full potential of their machine learning investments.
21.3. Model Serving and APIs
In the realm of machine learning, the journey does not end with the training of a model; it extends into the deployment phase, where the model is made available for inference. This crucial step, known as model serving, involves exposing machine learning models through APIs, allowing users or applications to make predictions in real-time. In this section, we will delve into the fundamental concepts of model serving, explore the various types of APIs, discuss the trade-offs involved in choosing an API protocol, and provide practical examples of implementing a model serving API in Rust using popular web frameworks like Actix and Rocket.
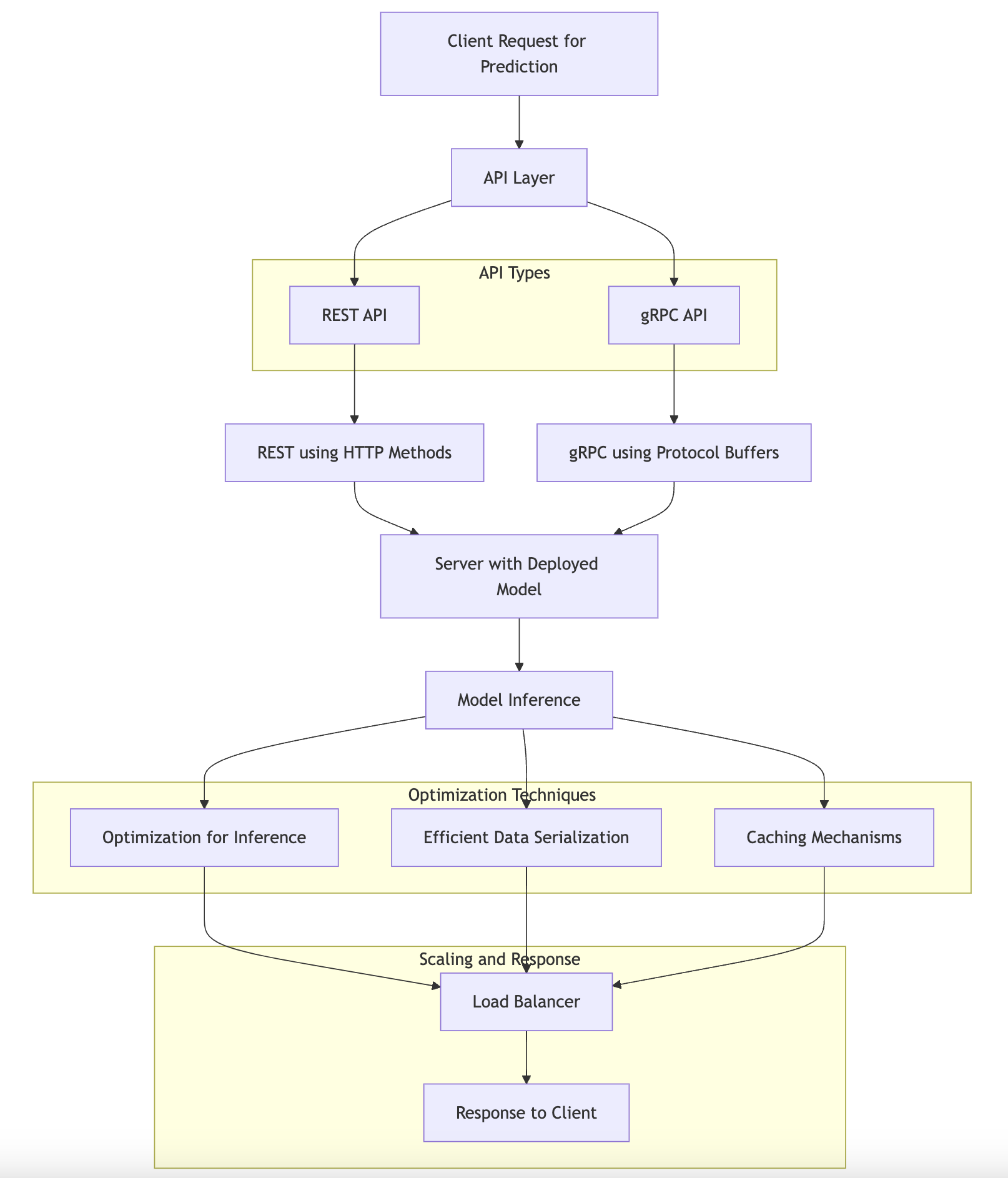
Figure 3: Common architecture of model serving APIs.
Model serving essentially revolves around creating an interface that allows external clients to interact with the machine learning model. The most common approach to achieve this is through APIs, which facilitate communication between the client and the server hosting the model. The two primary types of APIs used for model serving are REST and gRPC. REST (Representational State Transfer) is a widely used architectural style for designing networked applications. It is based on standard HTTP methods and is generally easier to integrate with various platforms and languages. On the other hand, gRPC (gRPC Remote Procedure Calls) is a high-performance, open-source framework that uses HTTP/2 for transport, enabling features such as multiplexing and bi-directional streaming. Both protocols have their advantages and drawbacks, which can influence the choice of one over the other depending on the specific requirements of the application.
When considering the trade-offs between different API protocols, several factors come into play. REST APIs are typically simpler to implement and more widely adopted, making them a preferred choice for many use cases. However, they can suffer from higher latency due to the overhead of HTTP and JSON serialization. In contrast, gRPC can offer lower latency and better performance due to its use of Protocol Buffers for serialization and HTTP/2 for transport. However, it introduces complexity in terms of setup and may require additional tooling. As such, when designing robust and scalable APIs for model serving, it is essential to evaluate the expected load, response time requirements, and the technical proficiency of the team.
Ensuring low-latency responses is paramount in model serving, especially for applications that require real-time predictions, such as fraud detection or recommendation systems. To achieve this, several strategies can be employed. These include optimizing the model for inference, using efficient data serialization formats, and implementing caching mechanisms. Additionally, load balancing and horizontal scaling of the serving infrastructure can help accommodate spikes in traffic without sacrificing performance.
To illustrate the practical implementation of a model serving API in Rust, we will create a simple RESTful API using the Actix framework. First, we need to add the necessary dependencies to our Cargo.toml file:
[dependencies]
actix-web = "4.0"
serde = { version = "1.0", features = ["derive"] }
serde_json = "1.0"
Next, we can create a basic Actix web server that serves a machine learning model. For demonstration purposes, let’s assume we have a pre-trained model that takes a single input feature and returns a prediction. Here’s how we can set up the API:
use actix_web::{web, App, HttpServer, Responder, HttpResponse};
use serde::{Deserialize, Serialize};
// Define the input structure for our model
#[derive(Deserialize)]
struct InputData {
feature: f32,
}
// Define the output structure for our model
#[derive(Serialize)]
struct OutputData {
prediction: f32,
}
// Dummy function to simulate model inference
fn predict(input: &InputData) -> OutputData {
let prediction = input.feature * 2.0; // Placeholder for actual model logic
OutputData { prediction }
}
// Handler for the prediction endpoint
async fn predict_handler(input: web::Json<InputData>) -> impl Responder {
let output = predict(&input);
HttpResponse::Ok().json(output)
}
// Main function to start the server
#[actix_web::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.route("/predict", web::post().to(predict_handler))
})
.bind("127.0.0.1:8080")?
.run()
.await
}
In this code, we define a simple Actix web server that listens for POST requests on the /predict endpoint. The predict_handler function takes JSON input, which is deserialized into the InputData struct. The predict function simulates model inference and returns an output, which is serialized back into JSON format for the response.
To deploy this API for real-time predictions, we would typically run it on a server or container orchestrator like Docker, ensuring that the server can handle concurrent requests and is appropriately scaled based on demand. Additionally, monitoring tools can be integrated to track the performance and health of the API, allowing for proactive adjustments as necessary.
In conclusion, deploying machine learning models through APIs is an integral part of the machine learning lifecycle. By understanding the fundamental principles of model serving, the trade-offs between different API protocols, and employing best practices in API design, we can create robust and efficient systems that deliver real-time predictions. Rust, with its performance and safety features, provides an excellent foundation for building these APIs, enabling developers to leverage their machine learning models effectively in production environments.
21.4 Continuous Integration and Continuous Deployment (CI/CD)
Continuous Integration and Continuous Deployment (CI/CD) have emerged as essential practices in modern software development, and their significance extends into the realm of machine learning. In the context of machine learning models, CI/CD allows for the automation of testing, validation, and deployment processes, ensuring that changes to models or data pipelines can be integrated smoothly and reliably. The fundamental idea behind CI/CD is to create a seamless workflow where code changes are automatically tested and deployed, minimizing human intervention and reducing the risk of errors.
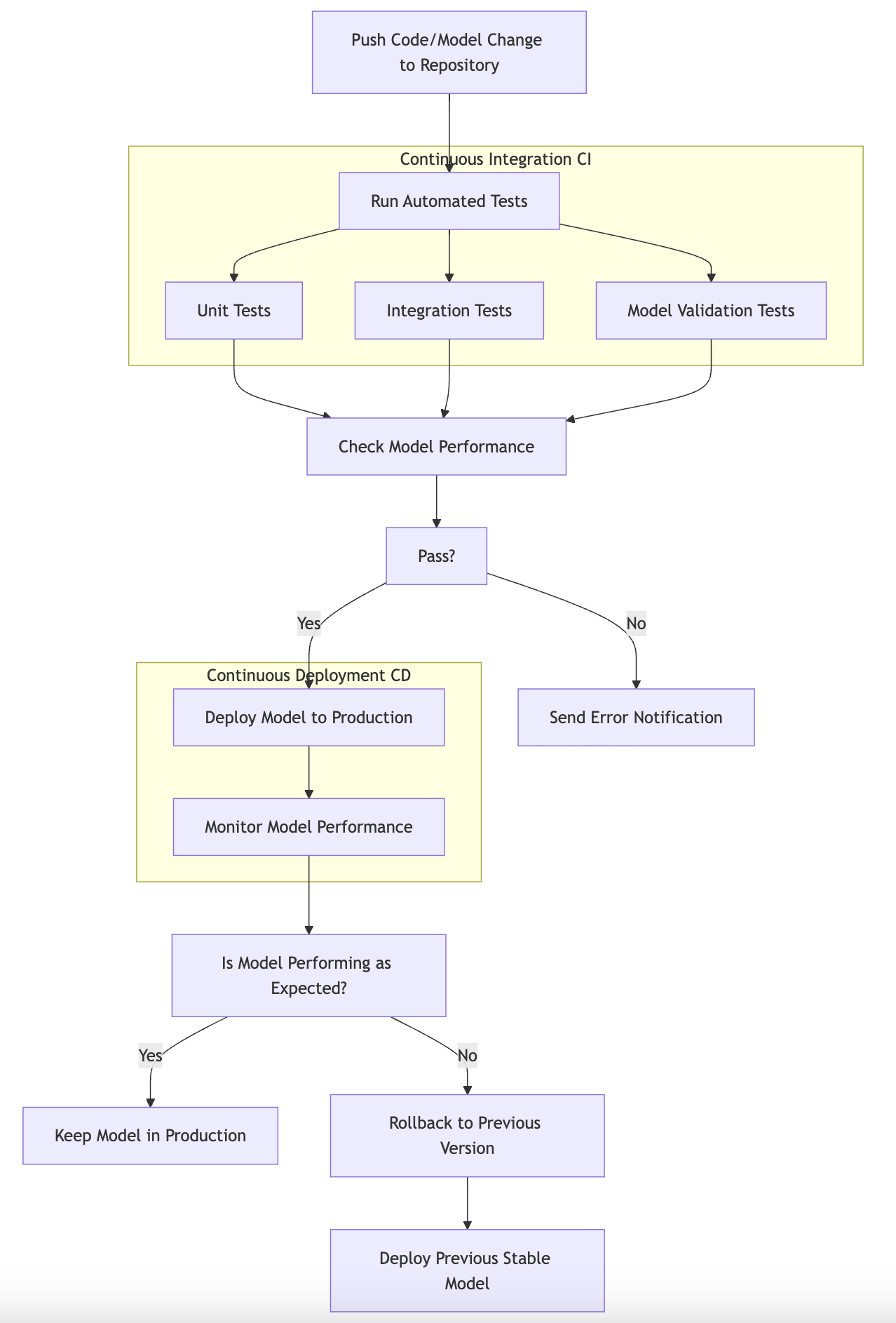
Figure 4: CI/CD process for ML model deployment.
Automated testing is a core component of CI/CD, especially for machine learning models. It involves running a suite of tests every time a change is made to the codebase. These tests can include unit tests for individual functions, integration tests for how components interact, and end-to-end tests that validate the entire workflow from data ingestion to model prediction. In the context of machine learning, it also includes model validation tests, which ensure that the model's performance meets the predefined metrics before it is deployed. This automated validation can help catch issues early in the development process, ensuring that only high-quality models make it into production.
In addition to automated testing, CI/CD practices in machine learning emphasize the importance of version control. Just as software developers use version control systems like Git to manage changes in their code, data scientists and machine learning engineers must also track changes to models, datasets, and training scripts. With version control, it becomes possible to roll back to previous versions of a model, which can be crucial if a newly deployed model underperforms or behaves unexpectedly. This rollback mechanism serves as a safety net, allowing teams to quickly revert to a stable state and minimize downtime or adverse effects on users.
To implement a CI/CD pipeline for machine learning models in Rust, one can utilize various tools such as GitHub Actions, Jenkins, or GitLab CI. These tools provide the necessary infrastructure to automate the testing and deployment processes. For instance, with GitHub Actions, you can define workflows that trigger on specific events, such as pushing code to a repository or creating a pull request. Below is a simple example of a GitHub Actions workflow file (.github/workflows/ci.yml) that demonstrates how to set up a CI/CD pipeline for a Rust-based machine learning project:
name: CI/CD for ML Models
on:
push:
branches:
- main
pull_request:
branches:
- main
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Set up Rust
uses: rust-lang/rustup@v1
with:
toolchain: stable
- name: Install dependencies
run: cargo build --release
- name: Run tests
run: cargo test
- name: Validate model performance
run: cargo run --bin validate_model
- name: Deploy model
if: github.ref == 'refs/heads/main'
run: cargo run --bin deploy_model
In this example, the workflow is triggered on pushes and pull requests to the main branch. It first checks out the code, sets up the Rust environment, and installs the dependencies. Following that, it runs the tests to ensure that the code is functioning correctly. The important step here is the model validation, which is executed via a separate binary that you would create (validate_model), in which you can implement checks on your model's performance metrics. Finally, if the code is pushed to the main branch, it proceeds to deploy the model using another binary (deploy_model), which can handle the deployment logic, such as uploading the model to a cloud service or a container orchestration platform.
In addition to GitHub Actions, tools like Jenkins or GitLab CI can also be configured similarly to automate the CI/CD process for Rust-based machine learning projects. The key is to establish a framework that allows for frequent integration and continuous delivery of machine learning models, thereby fostering a culture of rapid experimentation and iteration.
In conclusion, adopting CI/CD practices for machine learning models in Rust significantly enhances the reliability and efficiency of the development process. By leveraging automated testing, maintaining version control, and implementing rollback mechanisms, teams can ensure that their models are consistently of high quality and ready for deployment. Moreover, by setting up a robust CI/CD pipeline using tools like GitHub Actions, Jenkins, or GitLab CI, machine learning practitioners can streamline their workflows and focus more on innovation rather than manual processes.
21.5 Monitoring and Logging Deployed Models
In the realm of machine learning, deploying a model is only the beginning of the journey. Once a model is operational, its performance and behavior in a production environment become paramount. Monitoring and logging are essential practices that ensure the continued effectiveness of deployed models, providing insights that enable timely interventions when necessary. In this section, we will explore the fundamental ideas surrounding the importance of monitoring and logging in production environments, the key metrics to track, and the common challenges faced in maintaining deployed models. We will also delve into the conceptual ideas surrounding monitoring, particularly its role in detecting model drift, ensuring reliability, and enabling scaling based on demand. Finally, we will look at practical implementations of monitoring and logging for a deployed Rust-based model, utilizing tools such as Prometheus, Grafana, and Elasticsearch.
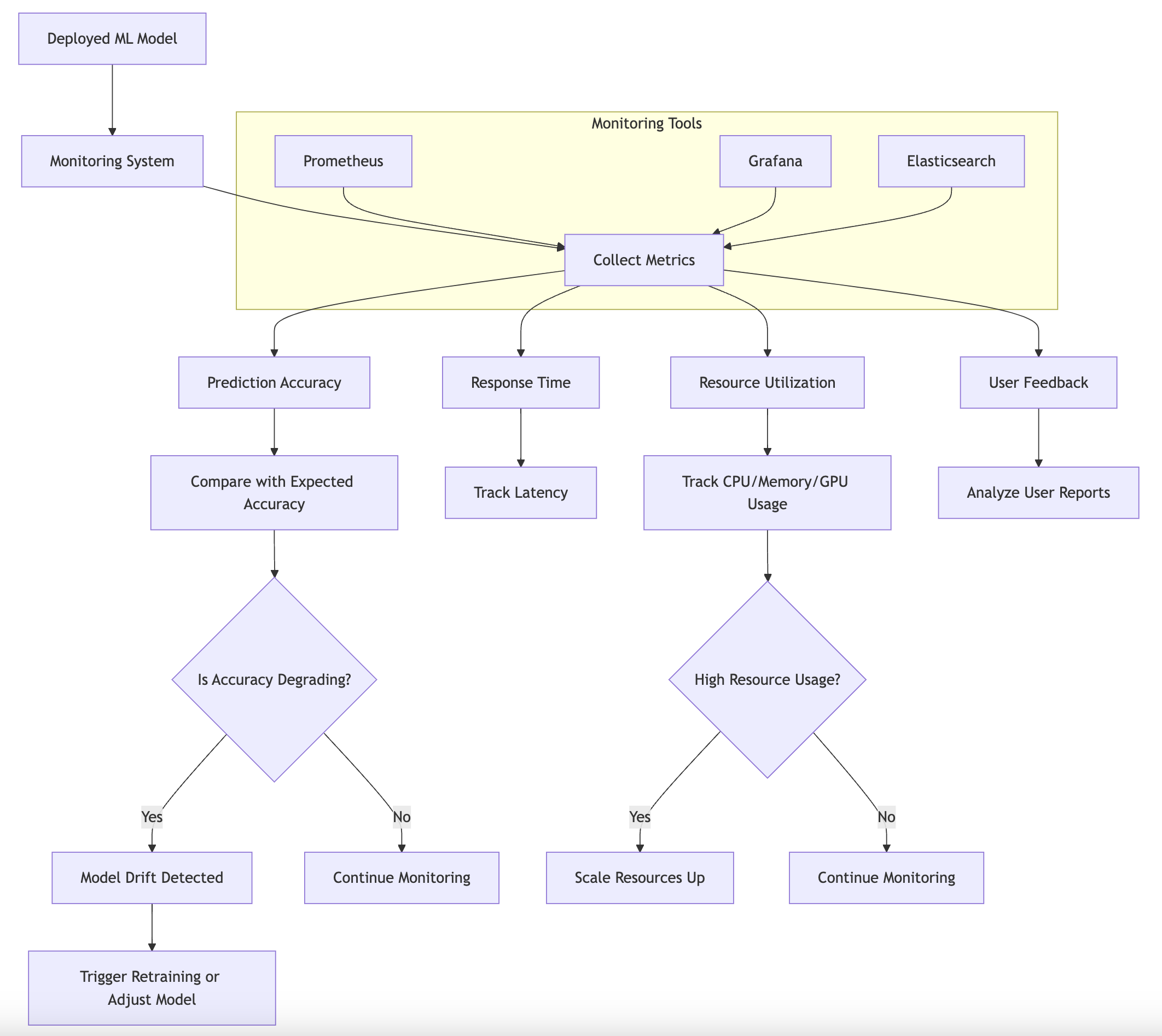
Figure 5: Logical monitoring architecture for deployed ML model.
Monitoring and logging are crucial in production environments because they allow data scientists and machine learning engineers to understand how their models are performing over time. Key metrics to track include prediction accuracy, response times, resource utilization (like CPU and memory usage), and user feedback. These metrics provide a comprehensive view of the model's health and performance, enabling teams to spot potential issues before they become critical problems. Common challenges include dealing with data drift, where the input data changes over time, leading to degraded model performance, and handling system failures or resource shortages that can affect response times and availability.
From a conceptual standpoint, monitoring plays a vital role in detecting model drift. Model drift occurs when the statistical properties of the input data change over time, which can significantly impact the model's accuracy. By continuously monitoring the input data and model predictions, teams can identify signs of drift and take appropriate actions, such as re-training the model with new data or adjusting its parameters. Additionally, monitoring ensures the reliability of the model in production. This includes tracking system performance and availability metrics, which help maintain service levels and ensure that the model can handle varying loads as demand fluctuates. This leads to the concept of scaling, which involves adjusting computational resources based on real-time demand to maintain optimal performance.
To implement effective monitoring and logging for a deployed Rust-based model, we can leverage powerful tools such as Prometheus, Grafana, and Elasticsearch. These tools can be integrated into our Rust application to track performance and detect anomalies. For example, we can use the prometheus Rust crate to expose metrics that Prometheus can scrape. Here’s a simple implementation that demonstrates how to set up a basic monitoring endpoint in a Rust web server application.
First, we need to add the necessary dependencies in our Cargo.toml:
[dependencies]
actix-web = "4.0"
chrono = { version = "0.4", features = ["serde"] }
prometheus = "0.11"
serde_json = "1.0"
elasticsearch = { version = "8.15.0-alpha.1", features = [] }
Next, we can create a simple Rust web server that exposes metrics:
use actix_web::{web, App, HttpServer};
use chrono::Utc;
use prometheus::{HistogramVec, Encoder, TextEncoder};
use serde_json::json;
use elasticsearch::{Elasticsearch, IndexParts};
use std::error::Error;
#[derive(Clone)]
struct AppState {
request_count: HistogramVec,
}
async fn metrics_handler(_data: web::Data<AppState>) -> String {
let metric_families = prometheus::gather();
let mut buffer = Vec::new();
let encoder = TextEncoder::new();
encoder.encode(&metric_families, &mut buffer).unwrap();
String::from_utf8(buffer).unwrap()
}
async fn prediction_handler(data: web::Data<AppState>, es: web::Data<Elasticsearch>) -> String {
data.request_count.with_label_values(&["POST", "/predict"]).observe(1.0);
let prediction = "42"; // Dummy prediction value
let result = "Success"; // Dummy result
// Log to Elasticsearch
log_prediction(&es, prediction, result).await;
let doc = json!({
"prediction": prediction,
"result": result,
"timestamp": Utc::now(),
});
doc.to_string()
}
async fn log_prediction(es: &Elasticsearch, prediction: &str, result: &str) {
let doc = json!({
"prediction": prediction,
"result": result,
"timestamp": Utc::now(),
});
let response = es.index(IndexParts::Index("predictions"))
.body(doc)
.send()
.await
.unwrap();
println!("Logged to Elasticsearch: {:?}", response);
}
#[actix_web::main]
async fn main() -> Result<(), Box<dyn Error>> {
// Initialize Prometheus metrics
let request_count = HistogramVec::new(
prometheus::opts!("request_count", "Number of requests made.")
.subsystem("http")
.into(),
&["method", "endpoint"]
).unwrap();
let state = AppState {
request_count,
};
// Create Elasticsearch client
let es = Elasticsearch::default();
// Start the server
HttpServer::new(move || {
App::new()
.app_data(web::Data::new(state.clone()))
.app_data(web::Data::new(es.clone()))
.route("/metrics", web::get().to(metrics_handler))
.route("/predict", web::post().to(prediction_handler))
})
.bind("127.0.0.1:8080")?
.run()
.await?;
Ok(())
}
In this example, we set up an Actix web server that exposes two endpoints: /metrics for Prometheus to scrape metrics and /predict for making predictions. The AppState struct contains a request_count histogram to track the number of requests made to the prediction endpoint. Each time a request is processed, we observe it in the histogram. This data can then be scraped by Prometheus at regular intervals to monitor the application’s performance.
To visualize the collected metrics, we can integrate Grafana with Prometheus. Grafana allows us to create dashboards that can provide real-time insights into model performance. By setting up alerts based on thresholds for key metrics, we can be proactively notified of any performance issues or anomalies, such as unexpected drops in accuracy or spikes in response times.
Finally, for centralized logging and advanced analysis, Elasticsearch can be integrated into our Rust application using the elasticsearch crate. This enables us to log prediction requests and their outcomes, which can then be queried and analyzed for patterns. Here’s a brief demonstration of how to log data to Elasticsearch:
use elasticsearch::{Elasticsearch, IndexParts};
use serde_json::json;
async fn log_prediction(es: &Elasticsearch, prediction: &str, result: &str) {
let doc = json!({
"prediction": prediction,
"result": result,
"timestamp": chrono::Utc::now(),
});
let response = es.index(IndexParts::Index("predictions"))
.body(doc)
.send()
.await
.unwrap();
println!("Logged to Elasticsearch: {:?}", response);
}
In this example, we define a function log_prediction that takes an Elasticsearch client and logs the prediction and its result along with a timestamp. This information can be invaluable for auditing model behavior over time and identifying any discrepancies between expected and actual outcomes.
In conclusion, monitoring and logging are indispensable aspects of managing deployed machine learning models. By actively tracking key metrics, detecting model drift, ensuring reliability, and scaling resources as needed, we can maintain high-performance and robust systems. The integration of Rust with monitoring tools like Prometheus, Grafana, and Elasticsearch provides a solid foundation for effectively managing the lifecycle of machine learning models in production, ensuring that they deliver consistent value over time.
21.6 Security and Privacy in Model Deployment
In the modern landscape of machine learning, deploying models into production environments brings forth a myriad of security and privacy considerations. As organizations leverage machine learning for a diverse array of applications, it becomes paramount to address the potential risks associated with the exposure of these models. Significant concerns include data encryption, access control, and adherence to regulatory compliance standards that govern the handling of sensitive data. This section delves into these fundamental ideas, paving the way toward a comprehensive understanding of the security and privacy landscape in model deployment.
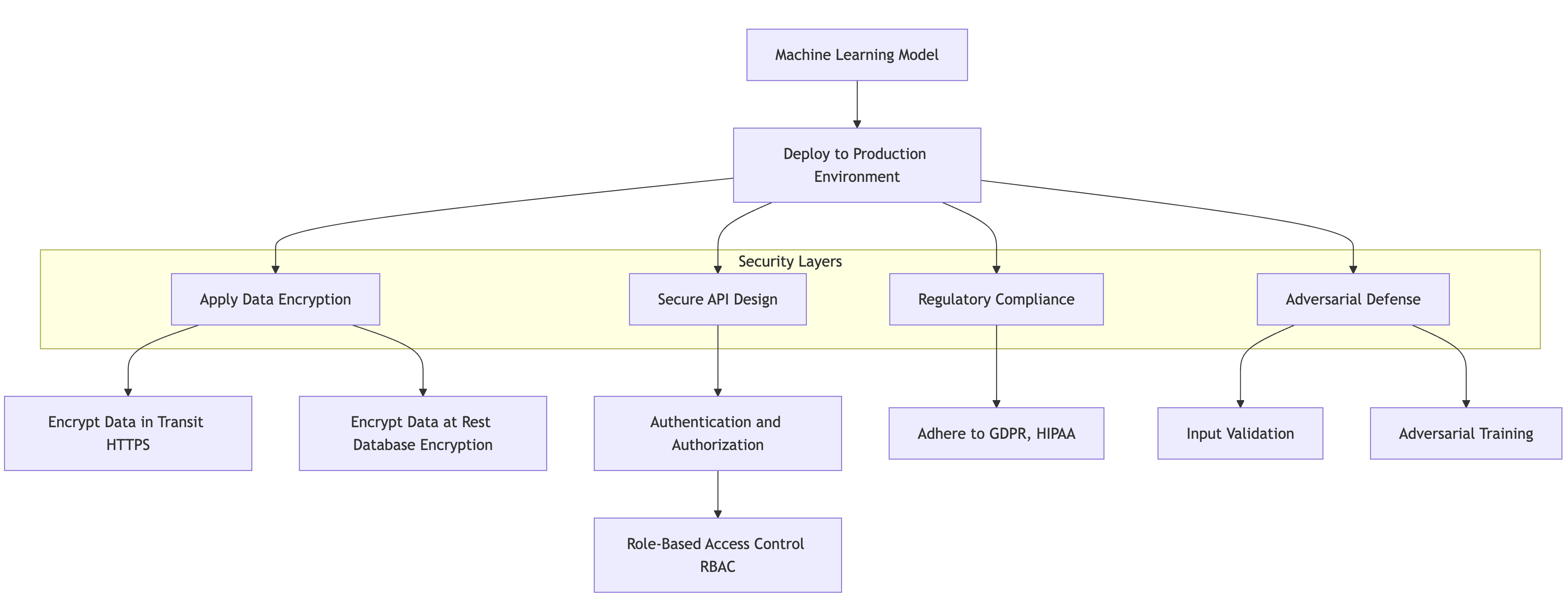
Figure 6: Logical security architecture of ML model deployment.
When deploying machine learning models, one must first recognize the inherent risks of exposing these models to external environments. Models can be vulnerable to various types of attacks, including adversarial attacks aimed at manipulating model predictions and data poisoning attacks that corrupt training datasets. These threats underscore the necessity of implementing robust security measures to protect both the models themselves and the data they process. Additionally, organizations must navigate the legal and ethical frameworks governing the use of data, especially when dealing with personally identifiable information (PII) or other sensitive data types. This includes understanding regulations such as the General Data Protection Regulation (GDPR) in Europe or the Health Insurance Portability and Accountability Act (HIPAA) in the United States, which impose strict guidelines on data privacy and protection.
To effectively mitigate these risks, it is essential to implement a multi-layered security approach when deploying machine learning models. In practical terms, this means incorporating security measures such as data encryption, authentication protocols, and secure API design. For instance, data encryption is vital for protecting sensitive information from unauthorized access. When transmitting data to a model via an API, using HTTPS ensures that the data is encrypted during transit, safeguarding it from potential eavesdropping. Furthermore, encrypting any sensitive data stored within the model’s database adds an additional layer of protection, ensuring that even if unauthorized access occurs, the data remains unreadable without the appropriate decryption keys.
In Rust, we can leverage various libraries to implement these security measures effectively. For example, the rustls crate provides a secure way to handle TLS (Transport Layer Security) connections, which is crucial for encrypting data in transit. Below is a simple example of how to set up a secure server using rustls:
use std::sync::Arc;
use rustls::{ServerConfig, NoClientAuth};
use std::fs::File;
use std::io::BufReader;
use tokio::net::TcpListener;
use tokio_rustls::TlsAcceptor;
#[tokio::main]
async fn main() {
let certs = load_certs("server_cert.pem");
let key = load_private_key("server_key.pem");
let mut config = ServerConfig::new(NoClientAuth::new());
config.set_single_cert(certs, key).expect("invalid key or certificate");
let acceptor = TlsAcceptor::from(Arc::new(config));
let listener = TcpListener::bind("127.0.0.1:8080").await.unwrap();
loop {
let (socket, _) = listener.accept().await.unwrap();
let acceptor = acceptor.clone();
tokio::spawn(async move {
let _ = acceptor.accept(socket).await;
});
}
}
fn load_certs(filename: &str) -> Vec<rustls::Certificate> {
let certfile = File::open(filename).unwrap();
let mut reader = BufReader::new(certfile);
rustls::internal::pemfile::certs(&mut reader).unwrap()
}
fn load_private_key(filename: &str) -> rustls::PrivateKey {
let keyfile = File::open(filename).unwrap();
let mut reader = BufReader::new(keyfile);
rustls::internal::pemfile::pkcs8_private_keys(&mut reader).unwrap().remove(0)
}
In this example, we set up a basic TCP listener that accepts incoming connections and wraps them in a TLS layer using rustls. This ensures that any data sent between the client and server is encrypted, thereby protecting it from interception or tampering.
Authentication is another critical aspect of securing machine learning model deployments. By implementing robust authentication mechanisms, we can ensure that only authorized users have access to the models. Rust provides several libraries, such as jsonwebtoken, for handling JSON Web Tokens (JWT), which can be used to authenticate API requests. Here’s a brief example of how we can validate a JWT in a Rust application:
use jsonwebtoken::{decode, DecodingKey, Validation, Algorithm, TokenData};
fn validate_token(token: &str) -> Result<TokenData<Claims>, jsonwebtoken::errors::Error> {
let validation = Validation::new(Algorithm::HS256);
let decoding_key = DecodingKey::from_secret("your_secret_key".as_ref());
decode::<Claims>(token, &decoding_key, &validation)
}
In this code snippet, we use the jsonwebtoken library to decode and validate a JWT. By requiring clients to include a valid token in their requests, we can restrict access to the machine learning model and ensure that only authenticated users can make predictions or access sensitive data.
Lastly, secure API design is crucial for protecting machine learning models deployed in production. This includes implementing rate limiting to protect against denial-of-service attacks, input validation to prevent injection attacks, and logging to monitor access patterns and detect anomalies. Rust's type safety and memory management make it an excellent choice for developing secure applications, as it helps prevent common vulnerabilities such as buffer overflows or null pointer dereferences.
In conclusion, the deployment of machine learning models necessitates a thorough understanding of security and privacy considerations. By implementing best practices such as data encryption, robust authentication, and secure API design in Rust, developers can create resilient systems that protect sensitive data while complying with legal and ethical standards. As the landscape of machine learning continues to evolve, it will be imperative for practitioners to stay informed about the latest security threats and mitigation strategies to safeguard their deployed models effectively.
21.7 Scaling and Load Balancing
In the realm of machine learning model deployment, scaling and load balancing are critical components that ensure your models can handle varying levels of traffic while maintaining performance and reliability. As applications evolve, the demand for predictions can fluctuate significantly; therefore, understanding and implementing effective scaling techniques is essential for any robust deployment strategy. This section will delve into the fundamental ideas surrounding scaling techniques, explore the conceptual underpinnings of horizontal and vertical scaling, and provide practical guidance on implementing scaling and load balancing for Rust-based models in cloud environments such as AWS, Azure, or Google Cloud.
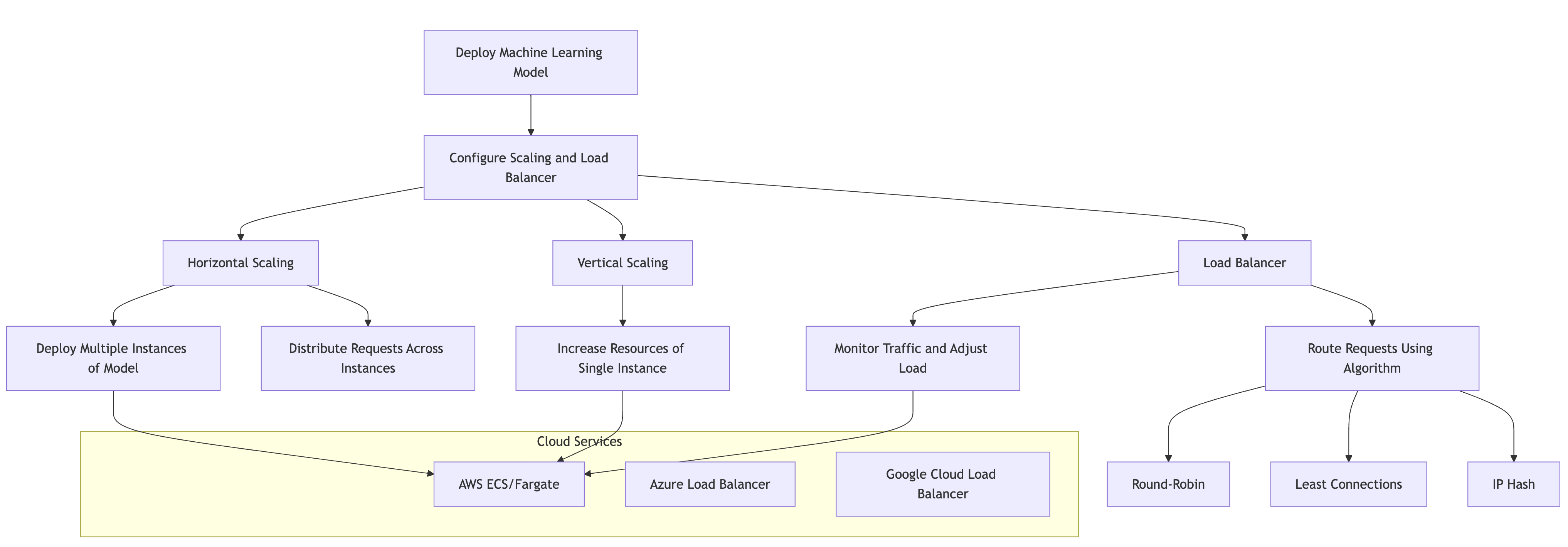
Figure 7: Logical architecture of ML model scaling and LB.
To begin with, it is important to recognize the two primary types of scaling: horizontal and vertical. Horizontal scaling, often referred to as scaling out, involves deploying additional instances of your machine learning model across multiple servers. This approach allows for the distribution of incoming requests among several instances, effectively spreading the load and enabling the application to handle increased traffic without a single point of failure. On the other hand, vertical scaling, or scaling up, involves enhancing the capacity of a single instance by increasing its resources, such as CPU, memory, or storage. While vertical scaling can provide immediate performance improvements, it has limitations in terms of maximum capacity and can create bottlenecks if traffic continues to grow.
In a production environment, load balancers play a crucial role in managing the distribution of traffic among various instances of your deployed model. A load balancer acts as an intermediary that routes incoming requests to multiple backend instances based on predefined algorithms. These algorithms can include round-robin, least connections, or IP hash, among others. By evenly distributing the workload, load balancers not only optimize resource utilization but also enhance the resilience of your application, ensuring that it can withstand sudden spikes in traffic without compromising performance.
When implementing scaling and load balancing for a Rust-based model, cloud services such as AWS, Azure, or Google Cloud provide powerful tools and services to streamline the process. For instance, using AWS, you can deploy your Rust-based machine learning model within a container using Amazon Elastic Container Service (ECS) or AWS Fargate. The deployment can be managed through an auto-scaling group, which automatically adjusts the number of instances based on predefined metrics such as CPU utilization or request count. This enables your application to dynamically scale up or down in response to real-time traffic demands.
As an example, consider a Rust-based web service that serves predictions from a trained model. You could structure your service using the Actix-web framework, which allows you to build a performant HTTP server in Rust. Below is a simplified implementation of a basic server that loads a model and serves predictions:
use actix_web::{web, App, HttpServer, Responder};
use serde::Deserialize;
use serde_json::json;
// Define the input data structure (matches the expected JSON input)
#[derive(Deserialize)]
struct MyInputData {
value: f64, // Example field, you can adjust this based on your needs
}
// Dummy model with a predict method
struct MyModel;
impl MyModel {
fn predict(&self, input: &MyInputData) -> f64 {
// Example prediction logic (you can replace this with your actual model logic)
input.value * 2.0
}
}
// Define the prediction endpoint
async fn predict(data: web::Json<MyInputData>) -> impl Responder {
let my_model = MyModel; // Create a model instance
let prediction = my_model.predict(&data); // Use the model to make a prediction
web::Json(json!({ "prediction": prediction }))
}
#[actix_web::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.route("/predict", web::post().to(predict)) // Route for the prediction endpoint
})
.bind("0.0.0.0:8080")? // Bind the server to port 8080
.run()
.await
}
In this code snippet, we define a simple HTTP server that listens for POST requests on the /predict route. The server receives input data in JSON format, processes it with the model, and returns the prediction in the response. To facilitate scaling, you would deploy this service in multiple instances across a cloud provider.
To configure load balancing, you would typically set up an AWS Application Load Balancer (ALB) that routes incoming traffic to your ECS instances. The ALB distributes requests based on the routing rules you define, ensuring that no single instance becomes a bottleneck. You can set up health checks to monitor the status of your instances, allowing the load balancer to redirect traffic away from unhealthy instances, thereby enhancing the reliability of your service.
For example, in the AWS Management Console, you would create a new Application Load Balancer, specify the target group for your ECS service, and configure the listener rules to forward requests to the target group. Moreover, you would set up auto-scaling policies based on CPU utilization, ensuring that new instances are launched or terminated automatically as traffic fluctuates.
In conclusion, effectively scaling and balancing the load of your machine learning models deployed in Rust is vital for ensuring high availability and performance. By leveraging horizontal and vertical scaling techniques, along with the capabilities of cloud providers and load balancers, you can build a resilient architecture that meets the demands of your application. As you continue to refine and enhance your deployment strategies, keep in mind the importance of monitoring and adjusting your scaling configurations to adapt to the ever-changing landscape of traffic and resource needs.
21.8 A/B Testing and Model Validation in Production
In the realm of machine learning, the deployment of models into production introduces a critical phase of ensuring that these models not only perform well in controlled environments but also maintain their efficacy when subjected to real-world conditions. One of the most effective methodologies for validating model performance in production is A/B testing. A/B testing, also known as split testing, involves comparing two versions of a model (or variants of a feature) to determine which one performs better based on a predefined metric. This section delves into the fundamental ideas surrounding A/B testing, the conceptual challenges encountered in real-world validation scenarios, and practical implementations of A/B testing for Rust-based machine learning models.
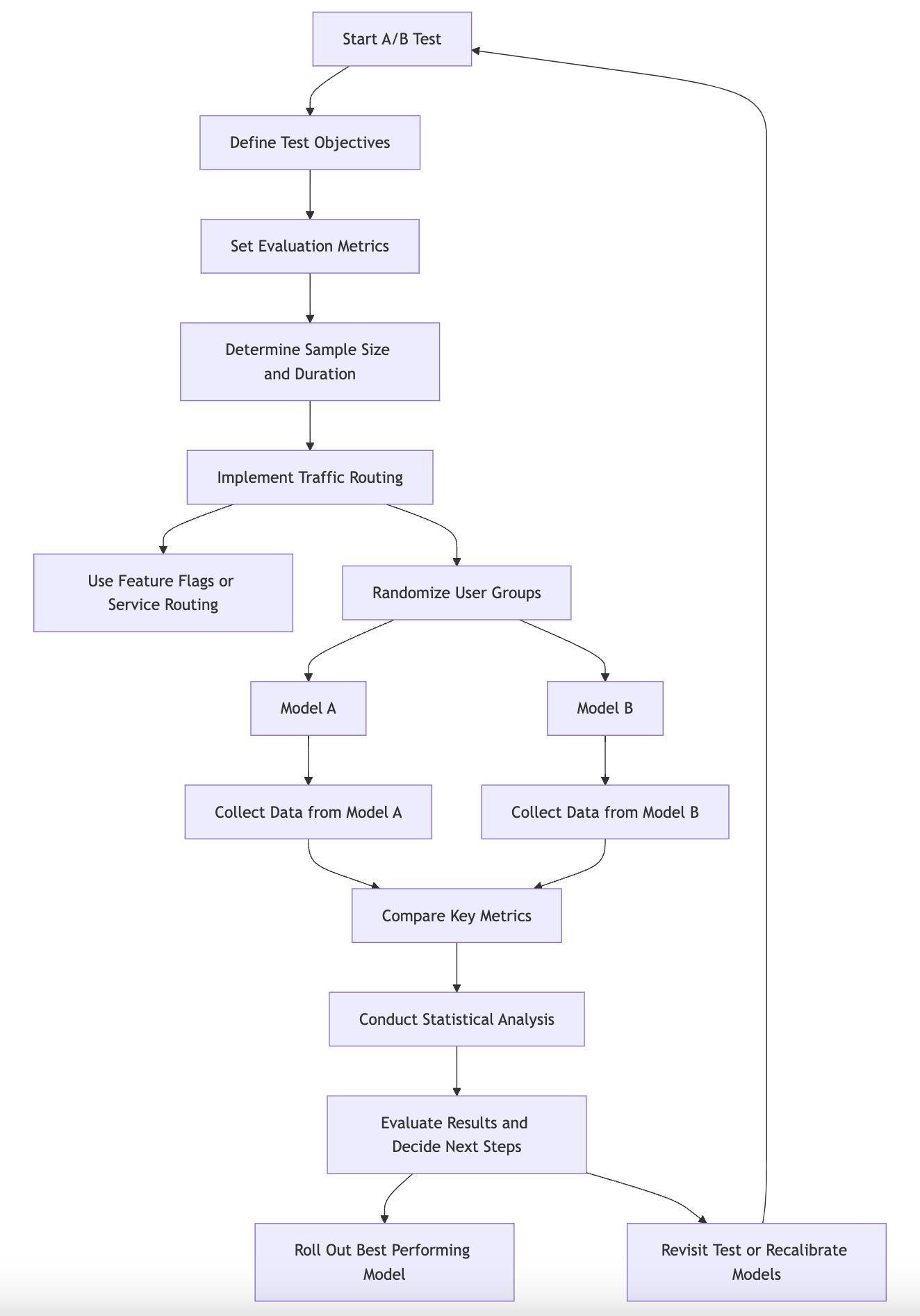
Figure 8: A/B testing process for deploying ML model.
The importance of A/B testing cannot be overstated. It serves as a systematic approach to decision-making by allowing data-driven comparisons between different model variants. In a production setting, this might involve deploying two distinct machine learning models or different configurations of the same model to a subset of users while observing their interactions and outcomes. For instance, one might deploy a new recommendation algorithm alongside the existing one to gauge user engagement or conversion rates. By collecting data on how each variant performs against key performance indicators (KPIs), teams can make informed decisions on which model to fully roll out.
Setting up an A/B test requires careful planning. It begins with defining the objectives of the test and selecting the appropriate metrics for evaluation. It's essential to determine the sample size and duration of the test to ensure that the results are statistically significant. Once the test parameters are established, the next step involves implementing the infrastructure to handle traffic routing between the different model variants. This may involve using feature flags to toggle between models or employing a service-oriented architecture where different services handle different models.
Interpreting the results of A/B testing can be complex, especially when the outcomes are influenced by external factors or user behaviors. It is crucial to avoid biases that may skew the results, such as selection bias, where the users exposed to one variant may inherently differ from those exposed to another. To mitigate such risks, randomization techniques should be employed to ensure that users are equally likely to be assigned to either group. Once the test concludes, statistical analysis methods, such as t-tests or Bayesian inference, can be utilized to evaluate the performance differences between the models.
When it comes to practical implementation, Rust provides a robust environment for building and deploying machine learning models, and integrating A/B testing capabilities can be accomplished seamlessly. One approach is to use Rust's powerful web frameworks, like Actix or Rocket, to create an API that serves predictions from different model variants. Below is an illustrative example of how one might set up a basic A/B testing framework using Actix:
use actix_web::{web, App, HttpResponse, HttpServer, Responder};
use serde::{Deserialize, Serialize};
use rand::Rng;
// Define the input data structure
#[derive(Deserialize)]
struct InputData {
value: f64, // Example field for input data, you can adjust as needed
}
// Define the prediction output structure
#[derive(Serialize)]
struct Prediction {
result: f64, // Example field for prediction result
}
// Handler function for making predictions
async fn predict(req: web::Json<InputData>) -> impl Responder {
let model_variant = rand::thread_rng().gen_range(0..2); // Randomly choose model 0 or 1
let prediction = match model_variant {
0 => model_0_predict(&req),
1 => model_1_predict(&req),
_ => unreachable!(),
};
HttpResponse::Ok().json(prediction)
}
// Logic for model 0 prediction
fn model_0_predict(input: &InputData) -> Prediction {
Prediction {
result: input.value * 1.5, // Example logic for model 0
}
}
// Logic for model 1 prediction
fn model_1_predict(input: &InputData) -> Prediction {
Prediction {
result: input.value * 2.0, // Example logic for model 1
}
}
#[actix_web::main]
async fn main() -> std::io::Result<()> {
HttpServer::new(|| {
App::new()
.route("/predict", web::post().to(predict))
})
.bind("127.0.0.1:8080")?
.run()
.await
}
In this code snippet, we create a simple Actix web server that routes prediction requests to one of two models based on random selection. Each model could be a distinct machine learning algorithm or a different version of the same model. The request handler receives input data, randomly selects a model variant, and returns the prediction.
To ensure that we accurately measure the performance of our models, we can implement logging or analytics within the prediction function to capture relevant metrics such as response times, user interactions, or conversion events. This data can later be analyzed to assess which model variant performs better in terms of user satisfaction and business goals.
In conclusion, A/B testing is a vital component of model validation in production, allowing practitioners to evaluate the real-world performance of machine learning models. By understanding the fundamental principles of A/B testing, acknowledging the challenges of validating models in dynamic environments, and implementing practical solutions using Rust, data scientists and engineers can ensure that their models deliver optimal performance and drive informed business decisions.
21.9. Conclusion
Chapter 21 equips you with the knowledge and skills necessary to successfully deploy machine learning models in production environments. By mastering these techniques in Rust, you will ensure that your models are not only performant and reliable but also secure and scalable, ready to deliver real-world value.
21.9.1. Further Learning with GenAI
By exploring these prompts, you will deepen your knowledge of the theoretical foundations, practical applications, and advanced techniques in model deployment, equipping you to build, deploy, and maintain robust machine learning models in production.
Explain the importance of model deployment in the machine learning lifecycle. How does deployment differ from training, and what are the key challenges involved in moving models to production? Implement a basic deployment pipeline in Rust.
Discuss the infrastructure requirements for deploying machine learning models. What role do cloud services, containerization, and orchestration tools play in scaling and managing deployed models? Implement a deployment environment using Docker and Kubernetes in Rust.
Analyze the process of model serving and the design of APIs for real-time predictions. How do different API protocols like REST and gRPC compare, and what are the best practices for ensuring low-latency responses? Implement a model serving API in Rust and deploy it for real-time inference.
Explore the concept of Continuous Integration and Continuous Deployment (CI/CD) for machine learning models. How do CI/CD practices ensure reliable and automated model deployment, and what are the key components of a CI/CD pipeline? Implement a CI/CD pipeline in Rust using GitHub Actions or Jenkins.
Discuss the importance of monitoring and logging in maintaining deployed models. What metrics should be tracked, and how can monitoring help in detecting model drift and ensuring reliability? Implement monitoring and logging for a Rust-based model using Prometheus and Grafana.
Analyze the security and privacy considerations in deploying machine learning models. How do data encryption, access control, and secure API design protect models and sensitive data in production? Implement security measures in Rust for a deployed machine learning model.
Explore the challenges of scaling and load balancing deployed models. How do horizontal and vertical scaling differ, and what role do load balancers play in distributing traffic and optimizing performance? Implement scaling and load balancing for a Rust-based model using cloud services.
Discuss the process of A/B testing and model validation in production environments. How does A/B testing help in comparing model variants and making data-driven decisions, and what are the challenges of conducting experiments in real-world scenarios? Implement A/B testing for a deployed Rust-based model.
Analyze the trade-offs between different deployment strategies, such as rolling deployments, blue-green deployments, and canary releases. How do these strategies differ in terms of risk, downtime, and rollback capabilities? Implement a deployment strategy in Rust and evaluate its effectiveness.
Explore the concept of model versioning and rollback mechanisms in deployment. How do version control and rollback strategies help in maintaining stability and recovering from failures in production environments? Implement model versioning and rollback in Rust using Git.
Discuss the role of inference optimization in deploying machine learning models. How do techniques like model quantization, pruning, and hardware acceleration improve inference speed and reduce latency? Implement inference optimization techniques in Rust for a deployed model.
Analyze the impact of latency and throughput on the performance of deployed models. How do latency and throughput constraints affect the design of deployment systems, and what strategies can be used to optimize these metrics? Implement latency and throughput optimization in Rust for a real-time model serving API.
Explore the challenges of deploying machine learning models in edge computing environments. How do edge deployments differ from cloud-based deployments, and what are the unique considerations for deploying models on edge devices? Implement an edge deployment pipeline in Rust.
Discuss the importance of monitoring model drift in production environments. How does model drift impact the accuracy and reliability of deployed models, and what techniques can be used to detect and mitigate drift? Implement model drift detection in Rust using monitoring tools.
Analyze the role of serverless architectures in deploying machine learning models. How do serverless platforms like AWS Lambda and Google Cloud Functions support model deployment, and what are the benefits and challenges of using serverless architectures? Implement a serverless deployment in Rust for a machine learning model.
Explore the concept of privacy-preserving machine learning in deployment. How do techniques like federated learning and differential privacy ensure data privacy in deployed models, and what are the challenges of implementing these techniques? Implement privacy-preserving techniques in Rust for a deployed model.
Discuss the process of automating model deployment workflows using Infrastructure as Code (IaC). How does IaC support scalable and repeatable deployments, and what are the best practices for managing deployment infrastructure using code? Implement IaC for a Rust-based deployment pipeline using Terraform or AWS CloudFormation.
Analyze the challenges of deploying models in multi-cloud or hybrid cloud environments. How do multi-cloud strategies ensure redundancy and flexibility, and what are the key considerations for deploying models across multiple cloud providers? Implement a multi-cloud deployment in Rust for a machine learning model.
Explore the future directions of research in model deployment. What are the emerging trends and challenges in deploying machine learning models, and how can advances in automation, security, and infrastructure contribute to more effective and reliable deployments? Implement a cutting-edge deployment technique in Rust for a real-world machine learning application.
Each prompt encourages you to think critically about the deployment process and to apply your knowledge to create scalable, secure, and reliable deployment systems. Embrace these challenges as opportunities to deepen your expertise, refine your skills, and push the boundaries of what you can achieve with Machine Learning Model Deployment in Rust.
21.9.2. Hands On Practices
By completing these tasks, you will gain hands-on experience with Deploying Machine Learning Models, deepening your understanding of their implementation and application in real-world environments.
Task:
Implement a Continuous Integration and Continuous Deployment (CI/CD) pipeline for a Rust-based machine learning model. Automate the processes of testing, validation, and deployment using tools like GitHub Actions, Jenkins, or GitLab CI.
Challenges:
Experiment with different CI/CD workflows and analyze their impact on deployment speed, reliability, and rollback capabilities.
Task:
Implement a model serving API in Rust using a web framework like Actix or Rocket. Deploy the API to a production environment for real-time predictions, ensuring low-latency and high-throughput responses.
Challenges:
Experiment with different API protocols, such as REST and gRPC, and analyze their impact on latency, throughput, and scalability.
Task:
Implement monitoring and logging for a deployed Rust-based machine learning model using tools like Prometheus, Grafana, and Elasticsearch. Track key metrics such as latency, throughput, and error rates, and set up alerts for anomalies.
Challenges:
Experiment with different monitoring strategies, such as monitoring model drift or performance degradation, and analyze their effectiveness in maintaining model reliability.
Task:
Implement a deployment pipeline for a Rust-based machine learning model across multiple cloud providers (e.g., AWS, Azure, Google Cloud). Ensure that the model is deployed redundantly across clouds to enhance reliability and flexibility.
Challenges:
Experiment with different multi-cloud deployment strategies, such as active-active and active-passive configurations, and analyze their impact on redundancy, failover, and cost.
Task:
Implement security measures for a deployed Rust-based machine learning model, focusing on data encryption, secure API design, and access control. Ensure that the deployment complies with security best practices and regulatory requirements.
Challenges:
Experiment with different security protocols, such as HTTPS, OAuth, and JWT, and analyze their effectiveness in protecting the model and data in production.
Embrace the difficulty of these exercises as an opportunity to refine your skills and prepare yourself for tackling complex deployment challenges using Rust.
Comments