Chapter 22
Machine Learning Operations in Cloud
"It is not the strongest or the most intelligent who will survive but those who can best manage change." — Charles Darwin
Chapter 22 of MLVR provides a robust and comprehensive guide to Machine Learning Operations (MLOps) in the Cloud, a critical aspect of modern machine learning practices. This chapter begins by introducing the fundamental concepts of MLOps, highlighting the importance of integrating machine learning with cloud infrastructure to automate and scale operations. It delves into the specifics of cloud infrastructure, covering the necessary resources and services required for deploying and managing machine learning models in a cloud environment. The chapter also emphasizes the role of CI/CD in automating the deployment and monitoring of models, ensuring that updates and improvements are seamlessly integrated into production. Additionally, it covers monitoring and observability, providing readers with the tools and techniques needed to track model performance and detect anomalies in real-time. Security and compliance are also addressed, offering strategies to protect sensitive data and adhere to regulatory standards. The chapter further explores scalability and resource management, governance and lifecycle management, and cost optimization, ensuring that machine learning models are not only effective but also efficient and secure in the cloud. By the end of this chapter, readers will have a deep understanding of how to implement and manage MLOps in the cloud using Rust, ensuring that their machine learning models are reliable, scalable, and cost-effective.
22.1. Introduction to MLOps in the Cloud
Machine Learning Operations, or MLOps, is a burgeoning field that seeks to bridge the gap between the development of machine learning models and their deployment in production environments. At its core, MLOps encompasses a set of practices that aim to automate and enhance the process of taking machine learning models from development to deployment and maintenance, ensuring that they deliver consistent and reliable results. The importance of MLOps cannot be overstated; as organizations increasingly rely on machine learning to derive insights and drive decision-making, the ability to efficiently manage the lifecycle of machine learning applications becomes paramount. In this context, the cloud plays a significant role by providing scalable infrastructure and services that facilitate automated machine learning operations. This chapter delves into the integration of DevOps principles with machine learning, highlighting how the cloud environment enhances the MLOps framework.
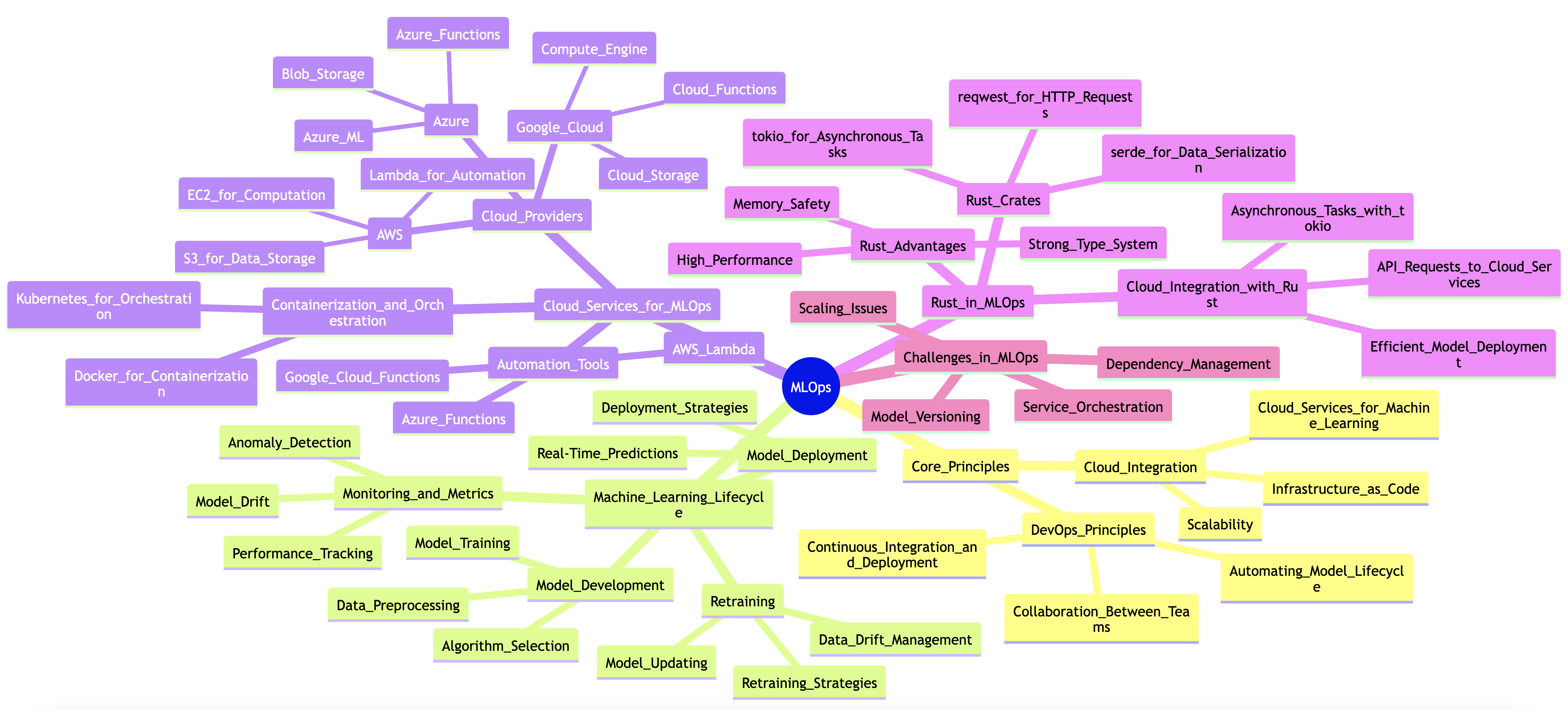
Figure 1: Complexity of ML Ops in Rust.
The lifecycle of a machine learning model in the cloud involves several critical stages, including model development, deployment, monitoring, and retraining. During the development phase, data scientists and machine learning engineers build and train models using various algorithms and datasets. Once a satisfactory model is developed, it must be deployed into a production environment where it can process new data and provide predictions or insights. Monitoring is a crucial aspect of this lifecycle as it involves tracking the model's performance, detecting anomalies, and assessing the quality of predictions over time. If the model's performance degrades due to changes in data distributions or other factors, retraining becomes necessary, which may involve revising the model architecture or updating the training dataset. However, implementing MLOps is not without its challenges. Organizations often face issues related to model versioning, dependency management, and the complexities of orchestrating multiple services in the cloud environment, which necessitates a robust strategy to overcome these hurdles.
Practically, setting up a basic MLOps pipeline in the cloud using Rust involves several key steps. First, one must establish a cloud environment, such as AWS, Google Cloud, or Azure, that provides the necessary resources for machine learning workloads. For instance, one can leverage cloud storage solutions to store datasets and trained models, while using compute instances for model training and inference. Rust, with its performance-oriented design and strong type system, is particularly well-suited for building efficient machine learning applications. To illustrate, one might create a simple Rust application that utilizes a cloud service for model deployment. The application could use the reqwest crate to make HTTP requests to a deployed model API, allowing for seamless integration and interaction with the model.
In addition to model deployment, automating routine tasks is a vital component of an MLOps pipeline. This can be achieved through the use of cloud services such as AWS Lambda or Google Cloud Functions, which enable the execution of code in response to specific triggers. For example, one could set up a scheduled job that periodically checks the performance of a deployed model and initiates a retraining process if necessary. By utilizing Rust's tokio crate, which provides asynchronous capabilities, the automation of these tasks becomes more manageable and efficient. With this approach, developers can ensure that their machine learning models remain up-to-date and continue to deliver high-quality predictions as new data comes in.
In summary, MLOps in the cloud represents a transformative shift in how organizations develop, deploy, and maintain machine learning models. By understanding the fundamental and conceptual ideas surrounding MLOps, as well as the practical steps involved in setting up an MLOps pipeline using Rust, practitioners can effectively harness the power of the cloud to optimize their machine learning operations. The integration of DevOps principles into the machine learning lifecycle not only streamlines processes but also enhances collaboration between data scientists and software engineers, ultimately leading to more robust and reliable machine learning solutions.
22.2. Cloud Infrastructure for MLOps
In the realm of Machine Learning Operations (MLOps), the foundational elements of cloud infrastructure play a pivotal role in ensuring that machine learning models are developed, deployed, and maintained efficiently and effectively. Cloud infrastructure provides a scalable and flexible environment for managing the various components required for MLOps, including compute resources, storage solutions, networking capabilities, and an array of managed services offered by leading cloud providers. By leveraging these resources, teams can accelerate their machine learning workflows and focus on delivering value rather than managing the underlying infrastructure.
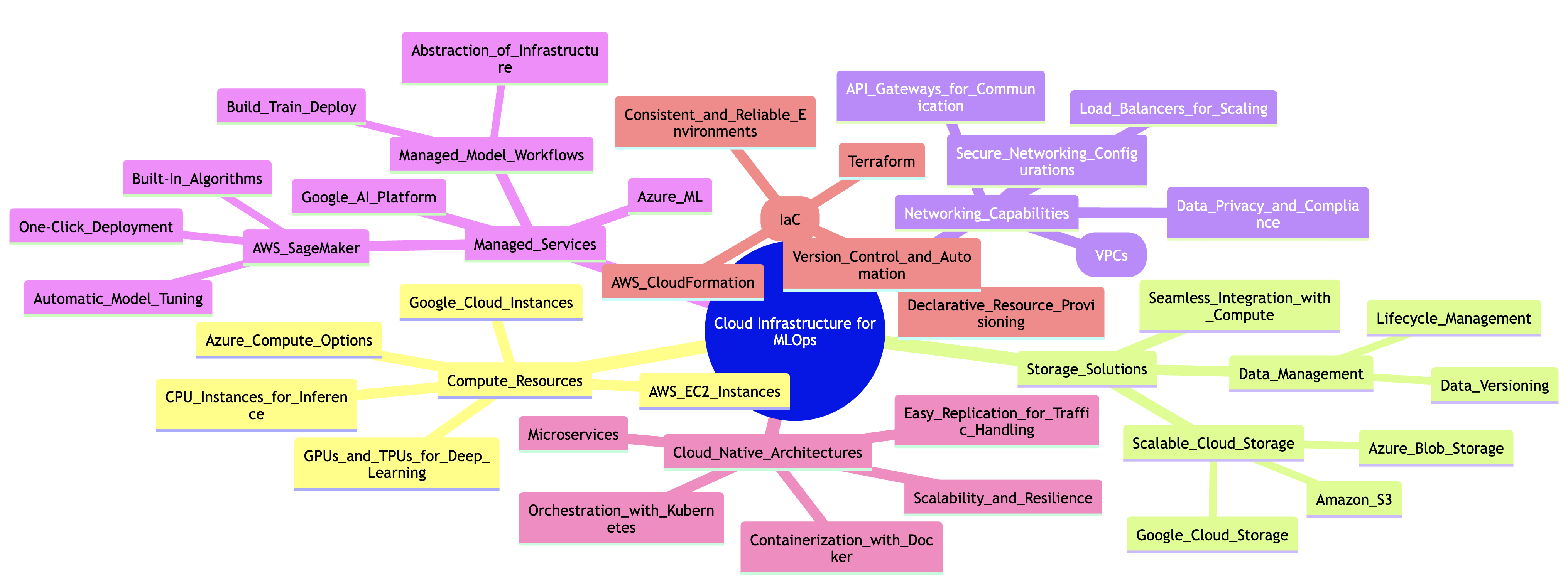
Figure 2: Complexity of Cloud Infra for ML Ops.
At the heart of cloud infrastructure for MLOps is the need for robust compute resources. Depending on the nature of the machine learning tasks, these resources can range from powerful GPUs and TPUs for training large-scale deep learning models to more modest CPU-based instances for simpler tasks. Cloud providers like AWS, Google Cloud, and Azure offer a variety of instance types that can be tailored to specific workloads, allowing teams to optimize cost and performance. For instance, using AWS EC2 instances, one can easily spin up a GPU-enabled instance for model training and then transition to a more cost-effective CPU instance for inference once the model is deployed.
In addition to computing resources, storage solutions are crucial for managing the large datasets often used in machine learning. Cloud storage services like Amazon S3, Google Cloud Storage, and Azure Blob Storage provide scalable storage solutions that allow teams to store, retrieve, and manage data efficiently. These services support various data formats and enable data versioning and lifecycle management, which are essential for maintaining the integrity of datasets over time. Furthermore, integrating these storage solutions with compute resources allows for seamless data access, facilitating rapid experimentation and iteration on machine learning models.
Networking capabilities are another key aspect of cloud infrastructure for MLOps. Cloud providers offer networking features such as Virtual Private Clouds (VPCs), load balancers, and API gateways that enable secure and efficient communication between different components of the MLOps pipeline. For instance, when deploying a model as a microservice in a cloud environment, a load balancer can distribute incoming requests across multiple instances of the service to ensure high availability and responsiveness. Additionally, setting up secure networking configurations helps safeguard sensitive data and ensures compliance with relevant data privacy regulations.
The use of managed services can greatly simplify the implementation of MLOps in the cloud. Services like AWS SageMaker, Google AI Platform, and Azure ML provide fully managed environments for building, training, and deploying machine learning models. These platforms abstract away much of the complexity associated with infrastructure management, allowing data scientists and machine learning engineers to focus on model development. For example, AWS SageMaker offers built-in algorithms, automatic model tuning, and one-click deployment capabilities, streamlining the entire machine learning workflow. By utilizing these managed services, teams can achieve faster time-to-market and reduce operational overhead.
From a conceptual standpoint, understanding cloud-native architectures is essential for designing effective MLOps pipelines. Cloud-native architectures leverage microservices, containerization, and orchestration to create scalable and resilient applications. Tools like Docker and Kubernetes enable teams to package their machine learning models and deploy them as containers, ensuring consistency across different environments. This approach not only simplifies deployment but also enhances scalability, as containers can be easily replicated to handle increased traffic or demand.
Infrastructure as Code (IaC) is another critical concept in the context of cloud infrastructure for MLOps. IaC allows teams to define and manage their cloud infrastructure using code, making it easier to version control, automate, and replicate environments. Tools like Terraform and AWS CloudFormation enable the declarative specification of cloud resources, allowing teams to provision and manage their infrastructure consistently and reliably. For instance, using Terraform, one can define the necessary compute instances, storage buckets, and networking configurations in a configuration file, which can then be applied to create the desired infrastructure with minimal manual intervention.
From a practical standpoint, implementing cloud infrastructure for MLOps using Rust and IaC tools like Terraform or AWS CloudFormation involves several steps. First, one would define the required resources in a Terraform configuration file. Below is a simplified example that creates an S3 bucket and an EC2 instance:
provider "aws" {
region = "us-west-2"
}
resource "aws_s3_bucket" "ml_data_bucket" {
bucket = "ml-data-bucket-unique-name"
acl = "private"
}
resource "aws_instance" "ml_instance" {
ami = "ami-0c55b159cbfafe1fe" # Example AMI
instance_type = "p2.xlarge" # GPU instance for training
tags = {
Name = "ML Model Training Instance"
}
}
This configuration, when applied, provisions an S3 bucket for data storage and an EC2 instance for model training. Once the infrastructure is set up, teams can deploy their machine learning models using cloud-based platforms. For instance, deploying a Rust-based model as a microservice can be achieved using AWS Lambda or a containerized solution in AWS ECS or EKS, allowing for efficient scaling and management of inference requests.
Managing resources efficiently in the cloud requires ongoing monitoring and optimization. Cloud providers offer various tools and services for monitoring resource usage, performance metrics, and cost management. By leveraging these tools, teams can make informed decisions about scaling resources up or down based on usage patterns, ensuring that they are not overspending on unused capacity while maintaining the performance needed for their applications.
In summary, the cloud infrastructure required for MLOps encompasses a wide range of components, including compute resources, storage solutions, networking capabilities, and managed services. Understanding cloud-native architectures, adopting Infrastructure as Code practices, and effectively utilizing managed services can significantly enhance the efficiency of machine learning workflows. By implementing these concepts in Rust and using IaC tools, teams can build robust and scalable MLOps pipelines in the cloud, ultimately driving innovation and delivering value in their machine learning initiatives.
22.3. Continuous Integration and Continuous Deployment (CI/CD)
In the realm of Machine Learning Operations (MLOps), the implementation of Continuous Integration (CI) and Continuous Deployment (CD) is a critical component that fosters the automation of testing, validation, and deployment processes for machine learning models in cloud environments. CI/CD is not merely a set of practices; it represents a paradigm shift in how machine learning projects are developed, tested, and delivered. By integrating CI/CD into an MLOps framework, teams can ensure that their models are consistently built, validated, and deployed with minimal manual intervention, significantly reducing the risk of errors and improving overall productivity.
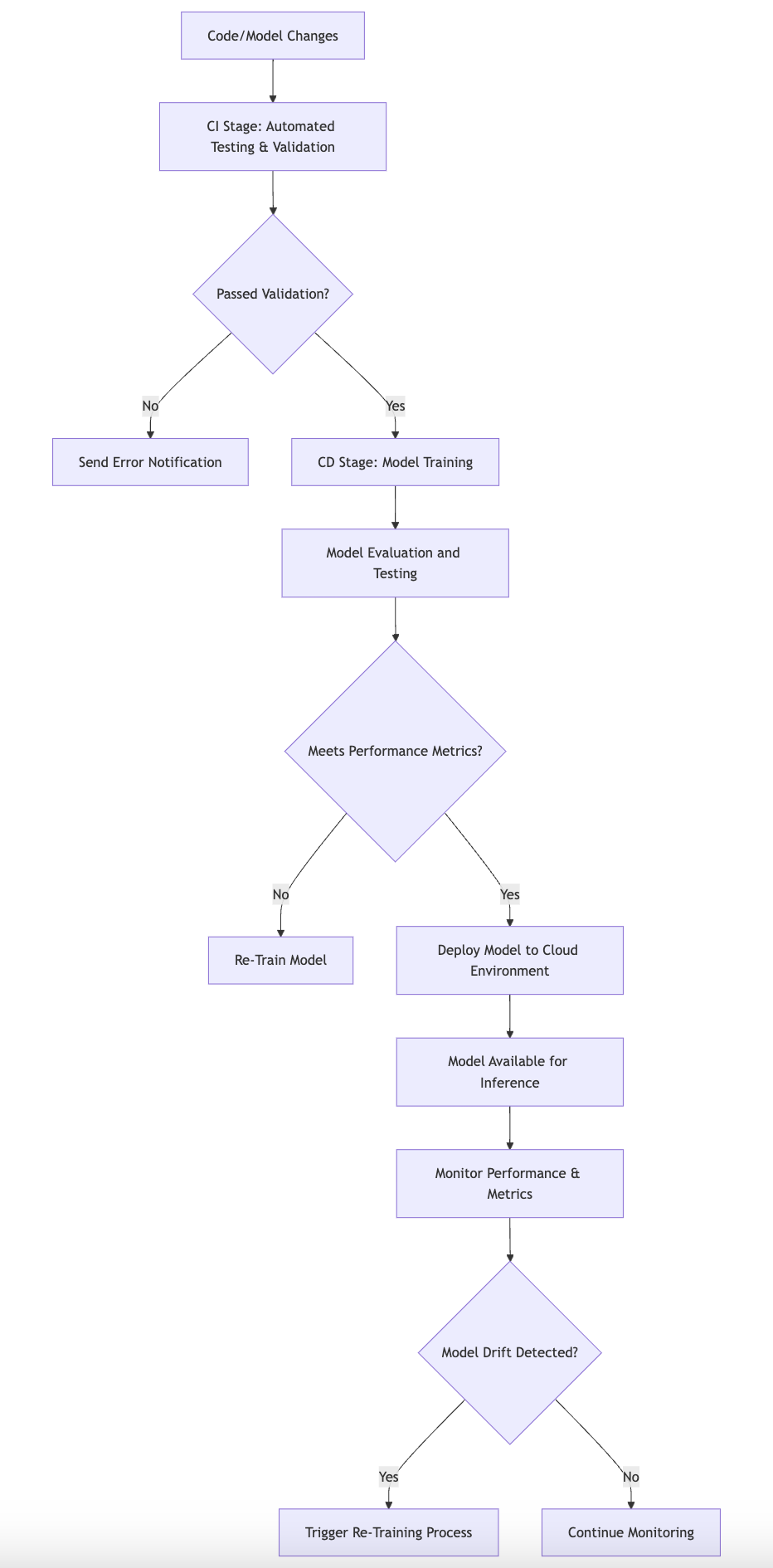
Figure 3: Cloud-based CI/CD process for ML model deployment.
The fundamental ideas behind CI/CD in MLOps revolve around the establishment of a reliable pipeline that encompasses various stages of the machine learning lifecycle. In this context, the CI process facilitates the continuous integration of code changes, ensuring that any modifications made to the model or its underlying data are automatically tested and validated. This automated testing phase serves as a safeguard, allowing teams to detect issues early in the development process, thus preventing potential bottlenecks in later stages. Once the model has successfully passed all tests, the CD process takes over, automating the deployment of the model to production environments. This automation not only accelerates the deployment cycle but also enhances the ability to monitor and manage deployed models in real time, ensuring that they perform optimally.
In conceptual terms, the pipeline stages in CI/CD for MLOps typically include several key components: data validation, model training, deployment, and monitoring. Data validation ensures that incoming data meets predefined quality standards before it is used for training. This step is crucial, as poor-quality data can lead to suboptimal model performance. Following data validation, the model training stage involves training the model on the validated data, often utilizing various hyperparameters and configurations to achieve the best performance. Once the model is trained, it enters the deployment phase, where it is published to a cloud environment, making it available for inference. The final stage, monitoring, involves continuously tracking the model's performance in production, allowing teams to identify any issues promptly and retrain the model if necessary.
To implement a CI/CD pipeline for MLOps in Rust, one can leverage cloud services such as AWS CodePipeline or Azure DevOps. These platforms offer robust tools for automating the various stages of the machine learning lifecycle. For instance, with AWS CodePipeline, you can configure a series of stages that automatically trigger actions based on specific events, such as code changes in a version control repository. Each stage can be tailored to execute tasks like running data validation scripts, initiating model training using a Rust-based machine learning library, and deploying the model to an AWS service such as SageMaker for real-time inference.
As an illustration, consider a simple example of a CI/CD pipeline built using AWS CodePipeline and Rust. The first step involves setting up a version control system, such as Git, where the Rust code for the machine learning model resides. Once the code is committed, AWS CodePipeline can be configured to automatically trigger the pipeline. The first stage in the pipeline can be a data validation step that utilizes a Rust script to check the integrity and quality of the incoming dataset. This script could leverage the ndarray crate to handle numerical data and perform checks for missing values or outliers.
use ndarray::Array2;
fn validate_data(data: Array2<f64>) -> bool {
for row in data.axis_iter(ndarray::Axis(0)) {
if row.iter().any(|&x| x.is_nan() || x.is_infinite()) {
return false; // Data contains invalid values
}
}
true // Data is valid
}
If the data validation passes, the pipeline can then transition to the model training stage. Here, you would employ a Rust machine learning library, such as linfa, to train your model. The linfa library provides various algorithms for supervised and unsupervised learning, allowing you to build and train a model efficiently.
use linfa::prelude::*;
use linfa_trees::{DecisionTree, DecisionTreeParams};
use ndarray::{Array1, Array2};
fn train_model(data: Array2<f64>, targets: Array1<usize>) -> DecisionTree<f64, usize> {
let dataset = Dataset::new(data, targets);
let model = DecisionTreeParams::default().fit(&dataset).unwrap();
model
}
Once the model is trained, the next step is to deploy it. This could involve packaging the model and sending it to AWS SageMaker, where it can be hosted for inference. Finally, to ensure that the model performs well in production, a monitoring stage can be implemented. Through AWS CloudWatch or similar monitoring tools, you can set up alerts for metrics such as prediction accuracy or latency, allowing for quick responses to any performance degradation.
In conclusion, the integration of CI/CD within the MLOps framework is vital for the successful deployment and management of machine learning models in the cloud. By automating the various stages of the machine learning lifecycle, organizations can achieve greater efficiency, enhance the quality of their models, and respond swiftly to changes in data or model performance. Leveraging cloud services and the Rust programming language allows teams to build robust, scalable, and maintainable CI/CD pipelines that can adapt to the evolving landscape of machine learning.
22.4. Monitoring and Observability in Cloud-Based MLOps
In the realm of Machine Learning Operations (MLOps), monitoring and observability are pivotal components that ensure the reliability and performance of machine learning models deployed in cloud environments. The fundamental ideas behind monitoring and observability revolve around the continuous tracking of model performance, the detection of drift, and the maintenance of model reliability once it is in production. As machine learning models are susceptible to various changes in data patterns and environmental conditions, a robust monitoring framework allows organizations to proactively address issues that may arise, ensuring that models continue to deliver accurate predictions over time.
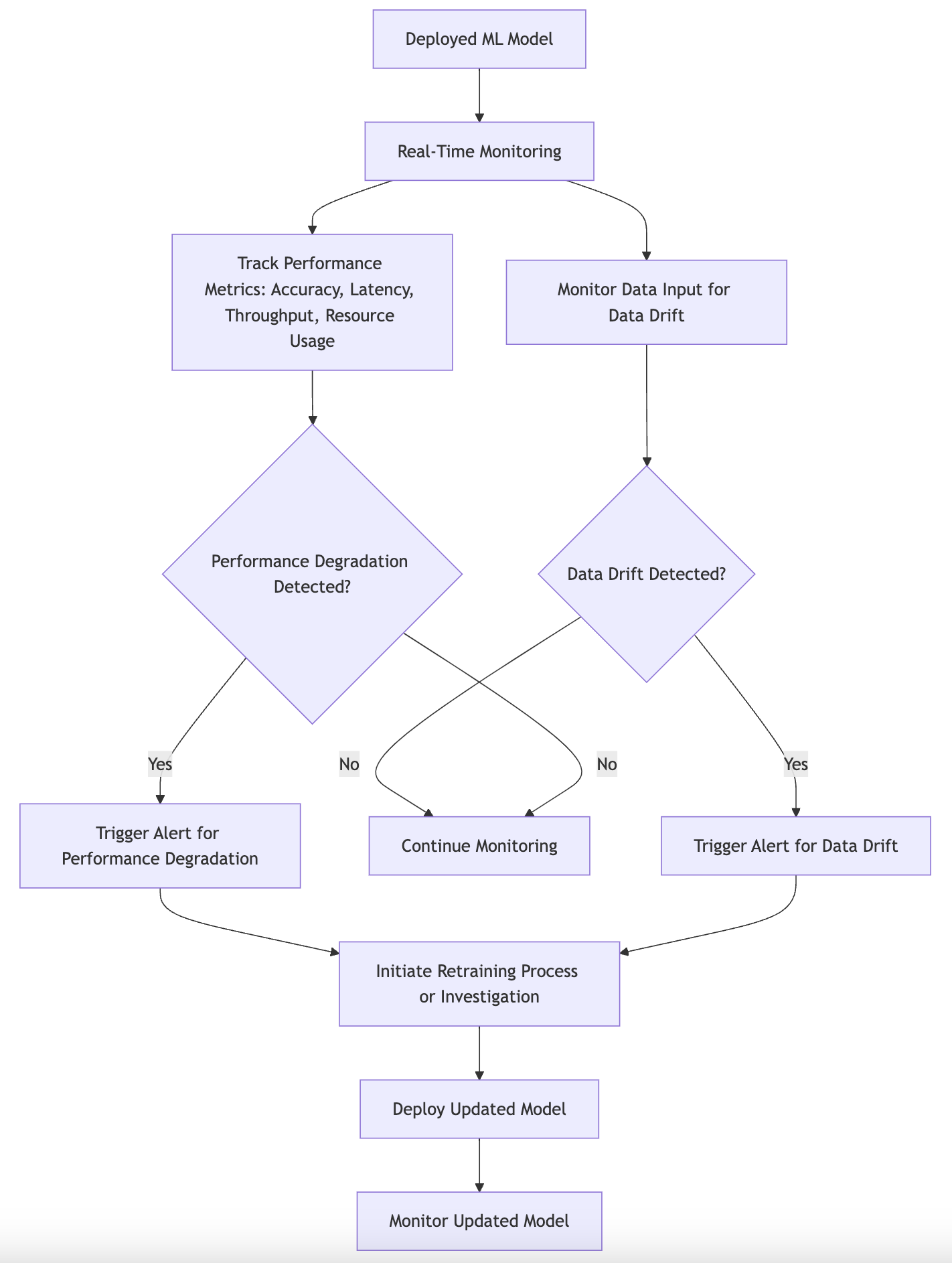
Figure 4: Logical architecture of monitoring and observability of ML model on Cloud.
When discussing the importance of real-time monitoring, it becomes evident that the agility of a cloud-based infrastructure allows for immediate feedback on model performance. Real-time monitoring enables data scientists and engineers to observe metrics such as latency, throughput, and accuracy as they occur, offering insights into how well the model is performing in a live setting. In addition to performance metrics, monitoring tools can track input data characteristics, allowing teams to identify when the incoming data diverges from the training distribution—an occurrence known as data drift. This drift can significantly impact model performance, making it essential to establish a system that automatically notifies stakeholders when such deviations are detected.
Setting up alerts for performance degradation is another critical aspect of monitoring in MLOps. Alerts act as safety nets that notify teams of potential issues before they escalate into significant problems. For instance, if a model's precision drops below a predefined threshold, an alert can trigger a workflow that initiates a retraining process or an investigation into the root cause of the degradation. Tools such as Prometheus, Grafana, and CloudWatch play an instrumental role in facilitating this monitoring and alerting system. Prometheus, with its powerful time-series database, excels in collecting metrics from various sources, while Grafana provides an intuitive interface for visualizing these metrics in real-time. CloudWatch, on the other hand, offers a comprehensive solution within the AWS ecosystem, allowing for seamless integration with other AWS services.
To implement monitoring and observability for Rust-based machine learning models deployed in the cloud, one can leverage the capabilities of the aforementioned tools alongside Rust libraries designed for metric collection and logging. For example, integrating the prometheus crate can facilitate the exposure of custom metrics from a Rust application. Below is a sample code snippet illustrating how to set up a simple Prometheus metrics server in a Rust application:
use prometheus::{Encoder, IntCounter, Opts, Registry, TextEncoder};
use std::net::SocketAddr;
use warp::Filter;
#[tokio::main]
async fn main() {
let registry = Registry::new();
let model_predictions = IntCounter::with_opts(Opts::new("model_predictions", "Number of model predictions made"))
.expect("Counter can be created");
registry.register(Box::new(model_predictions.clone())).unwrap();
let metrics_route = warp::path("metrics").map(move || {
let mut buffer = Vec::new();
let encoder = TextEncoder::new();
encoder.encode(®istry.gather(), &mut buffer).unwrap();
String::from_utf8(buffer).unwrap()
});
let addr = SocketAddr::from(([127, 0, 0, 1], 8080));
println!("Starting metrics server at http://{}", addr);
warp::serve(metrics_route).run(addr).await;
}
In this example, we create a basic HTTP server using the warp framework that exposes a /metrics endpoint. The endpoint will serve the metrics collected by Prometheus, such as the number of model predictions made. This setup allows for effective monitoring of the model's usage in production.
Furthermore, configuring alerts for anomalies can be accomplished through Prometheus alerting rules. By defining conditions under which alerts should trigger, teams can receive notifications via various channels, such as email or messaging platforms like Slack. A typical alerting rule can look like this:
groups:
- name: model-alerts
rules:
- alert: ModelPerformanceDegradation
expr: sum(rate(model_predictions[5m])) < 10
for: 5m
labels:
severity: warning
annotations:
summary: "Model performance degradation detected"
description: "The model has made less than 10 predictions in the last 5 minutes."
This rule checks if the rate of predictions falls below 10 per minute for a sustained period of 5 minutes, triggering an alert if the condition is met. Such configurations ensure that teams remain vigilant and responsive to changes in model performance.
To establish dashboards for real-time performance tracking, Grafana can be utilized to visualize the metrics collected from Prometheus. By creating custom dashboards, one can monitor key performance indicators (KPIs), such as accuracy and response times, providing a comprehensive view of the model's operational health.
In conclusion, monitoring and observability in cloud-based MLOps are essential for maintaining the integrity of machine learning models in production. By implementing real-time monitoring, setting up alerts for performance degradation, and utilizing tools like Prometheus and Grafana, organizations can ensure that their models remain reliable and effective over time. The integration of these practices into Rust-based applications not only enhances the observability of machine learning systems but also empowers teams to take proactive measures in the face of potential issues, fostering a culture of continuous improvement and responsiveness in the evolving landscape of machine learning.
22.5 Security and Compliance in Cloud MLOps
In the realm of Machine Learning Operations (MLOps), security and compliance have emerged as paramount considerations, particularly when deploying models in a cloud environment. The importance of safeguarding sensitive data cannot be overstated, especially given the increasing prevalence of data breaches and the stringent regulations governing data privacy. In this section, we will explore the fundamental concepts of security and compliance in cloud-based MLOps, delve into the conceptual challenges associated with deploying machine learning models, and provide practical implementations in Rust to ensure that security measures are effectively integrated into the MLOps pipeline.
The fundamental ideas surrounding security and compliance in cloud-based MLOps revolve around the protection of sensitive data, the enforcement of access controls, and adherence to regulatory standards such as the General Data Protection Regulation (GDPR) and the Health Insurance Portability and Accountability Act (HIPAA). When machine learning models are trained on sensitive data, it is crucial to ensure that this data is handled in accordance with legal and ethical guidelines. Data privacy is a significant concern, as unauthorized access to sensitive information can lead to severe repercussions, both for individuals and organizations. Access control mechanisms must be robust enough to prevent unauthorized users from accessing data or models, while also allowing necessary stakeholders to work efficiently.
Conceptually, deploying machine learning models in the cloud introduces a myriad of security challenges. One significant concern is the vulnerability of data during transmission and storage. Data breaches can occur if sensitive information is transmitted over unsecured channels. Therefore, encryption is vital to protect data in transit and at rest. Moreover, identity and access management (IAM) plays a critical role in ensuring that only authorized personnel can access sensitive resources. A well-defined IAM policy can help manage who can access what data and services, minimizing the risk of unauthorized access.
Additionally, secure API design is essential when exposing machine learning models as services in the cloud. APIs must be designed with security in mind, utilizing authentication and authorization mechanisms to ensure that only legitimate requests are processed. This includes implementing practices such as API keys, OAuth tokens, and rate limiting to mitigate abuse and ensure the integrity of the services.
To translate these conceptual ideas into practical implementations, we turn to Rust, a language known for its emphasis on safety and performance. Implementing security measures for MLOps in Rust involves leveraging its powerful libraries and features to enforce best practices in cloud security. For instance, Rust's openssl crate can be used to implement encryption for sensitive data. Below is a simple example of how to generate a keypair and encrypt and decrypt a message using RSA encryption in Rust:
use openssl::rsa::{Padding, Rsa};
use openssl::symm::Cipher;
fn main() {
// Generate keypair and encrypt private key:
let keypair = Rsa::generate(2048).unwrap();
let cipher = Cipher::aes_256_cbc();
let pubkey_pem = keypair.public_key_to_pem_pkcs1().unwrap();
let privkey_pem = keypair
.private_key_to_pem_passphrase(cipher, b"Rust")
.unwrap();
// pubkey_pem and privkey_pem could be written to file here.
// Load private and public key from string:
let pubkey = Rsa::public_key_from_pem_pkcs1(&pubkey_pem).unwrap();
let privkey = Rsa::private_key_from_pem_passphrase(&privkey_pem, b"Rust").unwrap();
// Use the asymmetric keys to encrypt and decrypt a short message:
let msg = b"Foo bar";
let mut encrypted = vec![0; pubkey.size() as usize];
let mut decrypted = vec![0; privkey.size() as usize];
let len = pubkey
.public_encrypt(msg, &mut encrypted, Padding::PKCS1)
.unwrap();
assert!(len > msg.len());
let len = privkey
.private_decrypt(&encrypted, &mut decrypted, Padding::PKCS1)
.unwrap();
let output_string = String::from_utf8(decrypted[..len].to_vec()).unwrap();
assert_eq!("Foo bar", output_string);
println!("Decrypted: '{}'", output_string);
}
In this example, we generate a keypair and encrypt the private key. The public key is then used to encrypt a message, which is decrypted using the private key. This implementation illustrates the fundamental encryption process necessary for securing sensitive data in transit and at rest.
In addition to encryption, implementing a robust IAM policy in Rust can be achieved using the jsonwebtoken crate for handling JSON Web Tokens (JWT). This library allows for secure user authentication and authorization in your MLOps API:
use serde::{Deserialize, Serialize};
use jsonwebtoken::{encode, decode, Header, Algorithm, Validation, EncodingKey, DecodingKey};
#[derive(Debug, Serialize, Deserialize)]
struct Claims {
sub: String,
exp: u64
}
fn create_jwt(user_id: &str, secret: &str) -> String {
let claims = Claims { sub: user_id.to_string(), exp: 10000000000 }; // Example expiration
encode(&Header::default(), &claims, &EncodingKey::from_secret(secret.as_ref())).unwrap()
}
fn validate_jwt(token: &str, secret: &str) -> bool {
let validation = Validation::new(Algorithm::HS256);
decode::<Claims>(token, &DecodingKey::from_secret(secret.as_ref()), &validation).is_ok()
}
In this example, we define functions to create and validate JWT tokens. The create_jwt function generates a token for a user, while the validate_jwt function checks the token's validity, allowing us to enforce access controls in our cloud-based MLOps pipeline.
In conclusion, as organizations increasingly rely on cloud-based MLOps, the importance of security and compliance cannot be overstated. By addressing fundamental ideas such as data privacy and access control, understanding conceptual challenges related to encryption and IAM, and implementing practical solutions in Rust, we can significantly bolster the security posture of machine learning operations in the cloud. Ultimately, prioritizing security and compliance not only protects sensitive data but also fosters trust and reliability in the deployment of machine learning models.
22.6. Scalability and Resource Management in Cloud MLOps
In the realm of Machine Learning Operations (MLOps), scalability and resource management are pivotal to ensuring that machine learning models can effectively handle varying workloads while maintaining optimal performance. As organizations increasingly rely on machine learning applications, the need for robust strategies that allow models to scale seamlessly and manage resources efficiently becomes paramount. This section delves into the fundamental concepts of scalability and resource management, the theoretical underpinnings of different scaling approaches, and practical implementations for Rust-based machine learning models deployed in the cloud.
Scalability in MLOps refers to the ability of a machine learning system to manage increased loads without compromising performance. This can be particularly challenging given the dynamic nature of user requests and the ever-growing datasets that machine learning models must process. Resource management, on the other hand, involves the strategic allocation of computational resources such as CPU, memory, and storage to ensure that these models perform optimally under varying operational conditions. Efficient resource management not only enhances performance but also optimizes cost, making it a critical consideration for organizations deploying machine learning solutions in the cloud.
To understand how to implement effective scalability and resource management, it is essential to explore the concepts of horizontal and vertical scaling. Horizontal scaling, often referred to as scaling out, involves adding more machines or nodes to distribute the load. This approach is particularly advantageous in cloud environments where resources can be dynamically provisioned. For instance, if a Rust-based machine learning model is deployed as a microservice, it can be replicated across multiple instances to manage a sudden surge in requests. Conversely, vertical scaling, or scaling up, entails upgrading existing machines with more powerful hardware. While this approach can enhance performance, it has limitations regarding maximum capacity and can often lead to service interruptions during upgrades.
Auto-scaling is an integral feature of cloud platforms that allows for the dynamic adjustment of resources based on current demand. By utilizing auto-scaling, organizations can ensure that their Rust-based machine learning models automatically scale up when there is increased load and scale down during periods of low activity. This not only helps in maintaining performance levels but also significantly reduces operational costs. Cloud providers like AWS, Azure, and Google Cloud offer built-in auto-scaling capabilities that can be configured to monitor specific metrics, such as CPU usage or request counts, and respond accordingly.
Another vital component of resource management in cloud MLOps is the use of container orchestration tools like Kubernetes. Kubernetes provides a robust framework for managing containerized applications, allowing developers to deploy, scale, and manage applications with ease. By deploying Rust-based models in Docker containers, organizations can take advantage of Kubernetes' powerful features for automated scaling, load balancing, and self-healing. For example, Kubernetes can automatically replicate a container running a Rust-based machine learning model if it detects that the current instance is under heavy load. This ensures high availability and resilience in production environments.
To implement scalability and resource management effectively in a cloud-based MLOps pipeline using Rust, developers can begin by containerizing their machine learning models. The following is a simplified example of a Dockerfile that can be used to package a Rust application:
# Use the official Rust image as the build stage
FROM rust:latest as builder
# Create a new directory for the application
WORKDIR /usr/src/rust-simple-page
# Copy the Cargo.toml and Cargo.lock files
COPY Cargo.toml Cargo.lock* ./
# Copy the source code
COPY src ./src
# Build the application in release mode
RUN cargo build --release
# Debugging step to check if the binary is created
RUN ls -la /usr/src/rust-simple-page/target/release
# Use Ubuntu as the final image to have a more recent glibc version
FROM ubuntu:latest
# Install required dependencies
RUN apt-get update && apt-get install -y libssl-dev ca-certificates && rm -rf /var/lib/apt/lists/*
# Copy the compiled binary from the builder stage
COPY --from=builder /usr/src/rust-simple-page/target/release/Rust-Simple-Page /usr/local/bin/rust-simple-page
# Expose port 8080
EXPOSE 8080
# Set the entrypoint
CMD ["rust-simple-page"]
Once the Rust application is containerized, it can be deployed to a Kubernetes cluster. The following YAML configuration can be used to define a Kubernetes Deployment, which specifies the number of replicas to run and enables auto-scaling:
apiVersion: apps/v1
kind: Deployment
metadata:
name: rust-ml-model
spec:
replicas: 3
selector:
matchLabels:
app: rust-ml-model
template:
metadata:
labels:
app: rust-ml-model
spec:
containers:
- name: rust-ml-model
image: myapp:latest
ports:
- containerPort: 8080
---
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: rust-ml-model-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: rust-ml-model
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50
In this example, the Deployment configuration specifies that three replicas of the Rust machine learning model should be running initially. The Horizontal Pod Autoscaler (HPA) is configured to monitor CPU utilization, automatically scaling the number of replicas between one and ten based on the load.
In conclusion, scalability and resource management are vital components of cloud MLOps that enable machine learning models to adapt to fluctuating demands while optimizing resource utilization. By understanding and implementing horizontal and vertical scaling, auto-scaling features, and container orchestration tools like Kubernetes, developers can ensure that their Rust-based machine learning applications are resilient, efficient, and cost-effective in a cloud environment. The combination of these strategies not only enhances performance but also positions organizations to respond proactively to the evolving landscape of machine learning applications.
22.7. Governance and Lifecycle Management in Cloud MLOps
In the realm of Machine Learning Operations (MLOps), particularly in cloud environments, governance and lifecycle management play critical roles in ensuring that machine learning models are not only effective but also compliant with regulatory standards and organizational policies. This section delves into the fundamental and conceptual ideas surrounding governance and lifecycle management, followed by practical implementation strategies in Rust. The emphasis will be placed on model versioning, audit trails, and maintaining the integrity of deployed models over time.
Governance in MLOps refers to the framework of policies, procedures, and controls that guide the management of machine learning models. It helps organizations maintain oversight over their ML assets, ensuring that models comply with legal, ethical, and operational standards. Lifecycle management, on the other hand, encompasses the processes involved in the development, deployment, monitoring, and retirement of models. Together, these two aspects form a cohesive strategy that addresses the complexities of managing multiple models in production environments.
One of the fundamental challenges in MLOps is the management of multiple models that may evolve over time. Each model may have different versions, configurations, and performance metrics, which can complicate deployment and monitoring efforts. Effective governance ensures that changes to models are tracked meticulously, enabling teams to maintain a clear understanding of the model's evolution and its impact on business outcomes. This includes version control systems that log every change made to a model, from hyperparameter adjustments to structural changes in the underlying algorithms. The ability to revert to previous versions of a model can be crucial in situations where a new version underperforms or behaves unexpectedly.
Audit trails serve as a vital component of governance, providing a comprehensive history of model development and deployment. They document not only the changes made to the model but also the rationale behind those changes. For instance, if a model is updated based on shifting data trends, an audit trail can elucidate the data sources used, the transformations applied, and the stakeholders involved in the decision-making process. This transparency is essential for compliance with regulations such as GDPR or HIPAA, where organizations must demonstrate accountability in their data usage and model decisions.
In terms of lifecycle management, continuous improvement is paramount. Machine learning models are not static; they need to be monitored and updated in response to new data and changing conditions. This requires a systematic approach to performance tracking, where metrics such as accuracy, precision, and recall are continuously evaluated against predefined thresholds. Implementing automated monitoring tools can help detect when a model's performance degrades, prompting a review or retraining process. This ongoing assessment not only ensures optimal performance but also facilitates compliance with governance standards.
To implement governance and lifecycle management practices for MLOps in Rust, we can utilize libraries such as serde for serialization, chrono for timestamping audit logs, and git2 for model version control. The following is a simplified example of how one might structure a governance and lifecycle management system in Rust:
use std::path::Path;
use serde::{Serialize, Deserialize};
use chrono::{DateTime, Utc};
use git2::{Repository, Error};
#[derive(Serialize, Deserialize)]
struct Model {
version: String,
parameters: String,
created_at: DateTime<Utc>,
}
struct AuditLog {
model_version: String,
change_description: String,
timestamp: DateTime<Utc>,
}
impl Model {
fn new(version: &str, parameters: &str) -> Self {
Self {
version: version.to_string(),
parameters: parameters.to_string(),
created_at: Utc::now(),
}
}
fn log_change(version: &str, description: &str) -> Result<AuditLog, Error> {
let log = AuditLog {
model_version: version.to_string(),
change_description: description.to_string(),
timestamp: Utc::now(),
};
// Here, you might want to append this log to a file or a database
Ok(log)
}
fn version_control(&self) -> Result<(), Error> {
let repo = Repository::open(".")?;
let mut index = repo.index()?;
// Assume you have a mechanism to add model files to the index
index.add_path(Path::new("model.json"))?;
index.write()?;
let signature = repo.signature()?;
let tree_id = index.write_tree()?;
let tree = repo.find_tree(tree_id)?;
let commit_id = repo.commit(
Some("HEAD"),
&signature,
&signature,
"Updated model version",
&tree,
&[],
)?;
Ok(())
}
}
fn main() {
let model = Model::new("1.0.0", "{\"learning_rate\": 0.01}");
match model.version_control() {
Ok(_) => println!("Model version logged successfully."),
Err(e) => eprintln!("Error logging model version: {}", e),
}
}
In this example, we define a Model struct that contains versioning information along with parameters and creation timestamps. The log_change method simulates logging an audit entry whenever a model is changed. The version_control method demonstrates how one might use Git to manage versioning, creating a commit every time a model is updated.
This approach to governance and lifecycle management in cloud MLOps not only fosters compliance and accountability but also equips organizations to adapt to changing environments through continuous learning and improvement. By employing Rust’s strong type system and concurrency capabilities, we can build efficient and reliable systems that effectively manage the complexities of machine learning models in production. Consequently, organizations can ensure the integrity of their deployed models while supporting innovation and compliance in an increasingly regulated landscape.
22.8. Cost Optimization and Efficiency in Cloud MLOps
In the era of advanced data science and machine learning operations (MLOps), the financial implications of deploying machine learning models in the cloud have grown increasingly significant. As organizations embrace the cloud for its scalability and computational power, understanding how to optimize costs while maintaining efficiency is paramount. Cost optimization in cloud-based MLOps entails not only managing cloud resources effectively but also developing a keen awareness of the financial landscape that governs the deployment of machine learning applications. This section delves into the fundamental, conceptual, and practical ideas surrounding cost optimization and efficiency in MLOps, particularly through the lens of Rust programming.
To begin with, the importance of cost optimization in cloud-based MLOps cannot be overstated. The cloud offers a plethora of services that enable organizations to train, deploy, and manage machine learning models at scale. However, this flexibility comes with a cost. Unmanaged usage of cloud resources can lead to significantly inflated bills that adversely affect the overall budget for machine learning projects. Therefore, it is essential to adopt a cost-conscious mindset when architecting MLOps pipelines, ensuring that every component, from data ingestion to model deployment, is optimized for cost efficiency. By managing cloud resources judiciously, organizations can achieve the dual goals of minimizing expenses while maximizing the performance and effectiveness of their machine learning operations.
When considering the conceptual aspects of cost optimization, one must recognize the inherent trade-offs between performance and cost. In many cases, the most performant solutions come with higher price tags. For example, using on-demand compute instances can deliver rapid results, but at a premium cost compared to spot instances, which may be less reliable but significantly cheaper. Spot instances are a compelling option for non-time-sensitive workloads, allowing users to leverage excess cloud capacity at reduced rates. Similarly, reserved instances offer a predictable cost structure for organizations that can commit to using specific resources over a longer term, often yielding substantial savings. Additionally, serverless architectures, such as AWS Lambda or Azure Functions, provide a way to run code without provisioning servers, allowing organizations to pay only for the compute time they consume, thus optimizing costs dynamically based on usage.
In practical terms, implementing cost optimization strategies in Rust for cloud-based MLOps involves leveraging various tools and techniques to monitor and control cloud spending. Rust, known for its performance and safety, can be an excellent choice for developing cloud-native applications. By incorporating libraries such as rusoto for AWS or azure-sdk-for-rust, developers can seamlessly interact with cloud services while embedding cost optimization practices into their codebase. For instance, when deploying a model with AWS, one might implement a function that checks the current pricing of instances and dynamically selects the most cost-effective option based on workload requirements. This could be achieved through a simple Rust application that queries the AWS pricing API and compares the costs of different instance types before initiating a training job.
To further enhance cost efficiency, organizations can also utilize cloud cost management tools that provide insights into spending patterns and resource utilization. Integrating such tools with Rust applications allows for real-time monitoring of cloud expenses. For example, setting up alerts for when spending exceeds predefined thresholds can help teams react swiftly to unexpected costs. By incorporating logging and monitoring libraries, such as log for Rust, developers can instrument their applications to capture relevant metrics and send them to cloud monitoring services. This data can then be used to inform decisions about resource allocation, scaling, and optimization strategies.
Moreover, configuring infrastructure to balance performance and cost-effectiveness is a critical aspect of cloud MLOps. This may involve employing auto-scaling strategies that adjust resource allocation based on current demand or implementing load balancers to distribute workloads efficiently across available instances. For example, a Rust-based deployment pipeline might include a configuration file that specifies the desired number of replicas for a machine learning model based on real-time traffic patterns. This setup enables the pipeline to scale in and out as needed, ensuring that resources are not wasted during periods of low demand while still being capable of handling spikes efficiently.
In conclusion, cost optimization and efficiency in cloud-based MLOps is a multifaceted challenge that requires a robust understanding of cloud economics, resource management, and performance trade-offs. By adopting a strategic approach to cloud resource utilization, leveraging the capabilities of Rust for building efficient MLOps systems, and implementing practical cost management strategies, organizations can navigate the complexities of cloud spending while driving innovation in their machine learning endeavors. As the landscape of cloud computing continues to evolve, embracing these principles will be crucial for organizations aiming to maximize the value of their investments in machine learning technologies.
22.9. Conclusion
Chapter 22 equips you with the knowledge and tools necessary to successfully implement and manage Machine Learning Operations in the cloud using Rust. By mastering these techniques, you will ensure that your machine learning models are not only performant and reliable but also secure, scalable, and cost-effective in a cloud environment.
22.9.1. Further Learning with GenAI
By exploring these prompts, you will deepen your knowledge of the theoretical foundations, practical applications, and advanced techniques in cloud-based MLOps, equipping you to build, deploy, and maintain robust machine learning models in a cloud environment.
Explain the concept of MLOps and its importance in the cloud. How does integrating DevOps principles with machine learning enhance the deployment, monitoring, and management of models? Implement a basic MLOps pipeline in Rust using cloud services.
Discuss the role of cloud infrastructure in supporting MLOps. What are the key components of a cloud infrastructure for machine learning, and how do managed services like AWS SageMaker and Google AI Platform simplify MLOps? Implement cloud infrastructure for MLOps using Rust and Terraform.
Analyze the importance of CI/CD in cloud-based MLOps. How do automated testing, validation, and deployment pipelines ensure reliable and continuous model updates? Implement a CI/CD pipeline in Rust for deploying machine learning models to the cloud.
Explore the concept of monitoring and observability in cloud-based MLOps. How do tools like Prometheus, Grafana, and CloudWatch help in tracking model performance and detecting drift? Implement monitoring and observability for a Rust-based model in the cloud.
Discuss the security challenges of deploying machine learning models in the cloud. How do encryption, access control, and compliance with regulations like GDPR and HIPAA protect models and data? Implement security measures in Rust for a cloud-based machine learning model.
Analyze the role of scalability and resource management in cloud-based MLOps. How do container orchestration tools like Kubernetes support auto-scaling and efficient resource allocation? Implement scalability and resource management for Rust-based models in the cloud using Kubernetes.
Explore the importance of governance and lifecycle management in MLOps. How do model versioning, audit trails, and lifecycle management practices ensure the integrity and continuous improvement of deployed models? Implement governance practices in Rust for managing machine learning models in the cloud.
Discuss the challenges of cost optimization in cloud-based MLOps. How do strategies like spot instances, reserved instances, and serverless architectures reduce cloud costs while maintaining performance? Implement cost optimization techniques in Rust for cloud-based machine learning operations.
Analyze the impact of Infrastructure as Code (IaC) on MLOps. How does IaC support scalable and repeatable deployments in the cloud, and what are the best practices for managing cloud infrastructure using code? Implement IaC for a Rust-based MLOps pipeline using Terraform or AWS CloudFormation.
Explore the concept of serverless computing in cloud-based MLOps. How do serverless architectures like AWS Lambda and Google Cloud Functions simplify the deployment and scaling of machine learning models? Implement a serverless deployment in Rust for a machine learning model.
Discuss the process of automating model retraining and updating in the cloud. How do CI/CD pipelines and automation tools ensure that models are continuously updated with new data and retrained to maintain accuracy? Implement automated model retraining in Rust using cloud services.
Analyze the importance of data management in cloud-based MLOps. How do data versioning, data governance, and data pipelines contribute to the reliability and reproducibility of machine learning models? Implement data management practices in Rust for cloud-based MLOps.
Explore the challenges of deploying machine learning models in multi-cloud environments. How do multi-cloud strategies enhance redundancy and flexibility, and what are the key considerations for deploying models across multiple cloud providers? Implement a multi-cloud deployment in Rust for a machine learning model.
Discuss the role of real-time monitoring in maintaining the performance of deployed models. How does real-time monitoring help in detecting anomalies, model drift, and performance degradation? Implement real-time monitoring for a Rust-based machine learning model in the cloud.
Analyze the impact of latency and throughput on cloud-based machine learning operations. How do these factors affect the performance and user experience of deployed models, and what strategies can be used to optimize them? Implement latency and throughput optimization in Rust for a cloud-based model serving API.
Explore the concept of federated learning in cloud-based MLOps. How does federated learning enable decentralized model training across multiple devices or nodes, and what are the challenges of implementing federated learning in the cloud? Implement federated learning in Rust using cloud services.
Discuss the challenges of integrating machine learning models with cloud-native applications. How do microservices architectures, containerization, and API gateways facilitate the integration of machine learning models into cloud-native environments? Implement cloud-native integration for a Rust-based machine learning model.
Analyze the role of edge computing in cloud-based MLOps. How do edge deployments differ from cloud-based deployments, and what are the unique considerations for deploying machine learning models on edge devices? Implement an edge deployment pipeline in Rust for a machine learning model.
Explore the future directions of research in cloud-based MLOps. What are the emerging trends and challenges in this field, and how can advances in cloud technologies, automation, and security contribute to more effective and reliable machine learning operations? Implement a cutting-edge MLOps technique in Rust for a real-world application.
Each prompt encourages you to think critically about the integration of machine learning and cloud technologies, and to apply your knowledge to create scalable, secure, and efficient MLOps pipelines.
22.8.2. Hands On Practices
By completing the following tasks, you will gain hands-on experience with Machine Learning Operations in the Cloud, deepening your understanding of their implementation and application in real-world environments.
Task:
Implement a cloud-native MLOps pipeline in Rust, focusing on automating the processes of model deployment, monitoring, and updating using cloud services like AWS SageMaker or Azure ML.
Challenges:
Experiment with different cloud services and automation tools to optimize the pipeline for performance, scalability, and reliability.
Task:
Implement a CI/CD pipeline in Rust for deploying machine learning models to the cloud, focusing on automating testing, validation, and deployment stages. Use cloud services like AWS CodePipeline or Google Cloud Build.
Challenges:
Experiment with different CI/CD configurations and analyze their impact on deployment speed, reliability, and rollback capabilities.
Task:
Implement monitoring and observability for a Rust-based machine learning model deployed in the cloud, using tools like Prometheus, Grafana, and CloudWatch. Track key metrics such as latency, throughput, and model drift.
Challenges:
Experiment with different monitoring strategies and tools, and analyze their effectiveness in maintaining model reliability and performance.
Task:
Implement a deployment pipeline for a Rust-based machine learning model across multiple cloud providers (e.g., AWS, Azure, Google Cloud). Ensure that the model is deployed redundantly across clouds to enhance reliability and flexibility.
Challenges:
Experiment with different multi-cloud deployment strategies, such as active-active and active-passive configurations, and analyze their impact on redundancy, failover, and cost.
Task:
Implement security and compliance measures for a Rust-based machine learning model deployed in the cloud, focusing on data encryption, access control, and adherence to regulatory standards like GDPR and HIPAA.
Challenges:
Experiment with different security protocols and compliance frameworks, and analyze their effectiveness in protecting models and data in the cloud.
Embrace the difficulty of these exercises as an opportunity to refine your skills and prepare yourself for tackling complex MLOps challenges using Rust in cloud environments.
Comments